













































What is Document Indexing & How to automate it?
Download the expert's guide to Document Indexing.
Many corporations that have shifted from paper to computer-based filing procedures have understood that digital files can be as disorganized and messy as analog ones. However, digitizing documents saves a lot of effort and time in the long run; it only functions if done correctly. That is where document indexing arrives.
Document indexing is an excellent way to enable your corporation to get your digital files organized and save future files organized. It also pertains to files involved in procedures across your institution, from accounts receivable and accounts payable to procure-to-pay.
What Is Document Indexing?

Document indexing organizes documents with proper tags or attributes for better visibility while searching or retrieving documents in the future.
For example, a firm might index documents by customer number, client name, employee name, date, or other vital traits that could be related later. It is a significant part of the foundation upon which an organization's document management networks are built.
Let's take an example of a dictionary. A dictionary comprises a broad range of words and their meanings. If you have to discover a particular work from the dictionary, looking at every page would take hours.
But by utilizing the index, your hunt shrinks to just minutes or seconds. Document indexing regulates a similar hypothesis. By attaching particular tags to a digital document, you can utilize the terms in those tags to more effortlessly find the information you require, rather than manually analyzing through a mountain of files.
Document Indexing Concepts
One can understand and know about document indexing in several concepts. Let’s briefly visit them:
- Database: A database is an electronic collection of documents kept in one place and made accessible to many users for many different purposes. It might also be an organized collection of documents or data stored on a computer, which a program can use to discuss and provide quick, flexible answers to inquiries.
- RDBMS: The term "RDBMS" (Relational Database Management System) refers to a database management system where data and the relationships between the data are maintained in tables.
- Key fields—index fields—are database fields used to categorize and arrange documents. They are typically defined by the user and can be used to scan and retrieve documents. Examples include the invoice number, the customer's name, the date, and the address.
- Match, merge, and fill indexing areas with index data already existing in other systems, such as accounting systems. It allows you to index one or more fields and automatically fill in the remaining fields with data from a table lookup or text file provided by another network, such as an accounting or human resources system, that matches.
Index documents automatically with no-code workflows in 15 minutes. See how it works with a free product demo where we will set workflows for you.
Get a free product tour or Start your free trial.
Why Is Document Indexing Important?
Document indexing enables more than just quick document retrieval. There are many advantages to document indexing, including the following:
Enhanced Document Organization
Employees can save time searching for the right document with the right document indexing system.
Easier audit compliance
You may easily dispense with the scramble to gather papers in time for an audit if the documents are already indexed and organized according to the fiscal year and other pertinent metrics.
Saves time
However, if you and your team have the proper document indexing protocols, you may use the time you spend searching for productive work.
Types of Document Indexing
In addition to the many benefits of document indexing, there are many different indexing approaches, so you can choose whatever one (or a combination of ways) best suits your document workflow. These strategies consist of the following:
Full-Text Indexing
With full-text indexing, the entire contents of a document are scanned, allowing you to search anywhere in the text for phrases or keywords.
It is identical to the "Find" (Ctrl+F or Command+F) tool included in most word processors and web browsers. The user-friendly nature of this indexing type makes it the easiest, but it requires a lot of storage space.
You can make documents searchable using Nanonets. See how.

Automated Indexing
Automated indexing, also known as variable lookup indexing, selectively indexes essential portions of a document that match up with a database, such as customer numbers or names, instead of indexing the entire page.
This procedure uses document indexing software. Still, it may be beneficial for businesses to index documents like bills that always include fields that match data in databases.
See how you can automate document indexing with Nanonets.
Metadata Indexing
"Data about data" is a term that's frequently used to refer to metadata, but it's very detailed. An example of this could be while capturing images to make a PDF file; it captures the time when it's taken.
Moreover, it also allows you to add additional "tags, " known as PDF metadata. Metadata, such as tags and other information you want to utilize for later searches, can be used while digitizing or scanning a document. Then, when it comes to obtaining a document, it scans the metadata rather than using your document retrieval program to scan entire documents.
Automated Indexing Using Field Data
Field-based indexing refers to various data sources within a database, also known as fields. It is conceptually identical to metadata indexing. For instance, you can use field-based indexing to search your database for records with the same name in the customer column.
Document indexing isn't tricky. Use all the above methods to index documents on autopilot.
See how you can automate document indexing with Nanonets in <15 minutes.
Get a free product tour or Start your free trial.
How does Document Indexing work?
Which document indexing is best for you will depend on how each of the involved parties intends to use the documents you are indexing. The information that employees are most likely to look up online and the search terms they are most likely to use to find it must be known to you. Understanding employee needs is the only way to ensure you are indexing in a way that will make speedy document retrieval possible.
It is simple to index the documents once you understand how your indexed papers will be used and which type of indexing makes the most sense for your organization. The indexing process entails scanning and categorizing digitized and scanned materials to locate predetermined key phrases manually or automatically. An explanation of the indexing process in more depth is provided below:
Understand Document Indexing Use Case
The type of indexing you should use will depend on the documents you are indexing, whether they are personnel records, invoices, or something else; knowing who will be retrieving these documents and why is also important.
Finalize the type of document indexing you want to use
It's possible that some types of papers can be easily found without needing as much information to be indexed. For example, you could only need the basic information from invoices, like the account number or vendor name.
Index the applicable data
You can index the data manually or, preferably, rely on the software that could index the data after determining what form of indexing makes sense.
The double key method is the most effective indexing technique when done manually. Two individuals tag each scanned document using this method with the necessary indexing phrases by entering the information they see into the appropriate metadata fields for the file. This makes it possible for a cross-comparison to find any errors. The double key saves a lot of time and drastically cuts down on mistakes.
You must specify the guidelines for which parts of the document the software should take from if you rely on software. For example, the right document indexing software collaborates with OCR technology to allow the computer to read text from images, which is crucial for indexing pertinent data and digitizing physical copies of documents.
Nanonets - The best Document Indexing Software
Nanonets is an AI-based document management system that allows users with a no-code platform for end-to-end document management. Nanonets automates all document processes like
- Document Upload
- Document Data Capture
- Document OCR
- Document Classification
- Document Verification
- Document Sorting
- Document Indexing
- Document Storage
- Document workflows
And more. Nanonets has an in-built OCR software that uses keyword extraction to identify documents and index them accordingly to the respective databases. Nanonets AI document processing technology learns with time and easily handles unstructured, semistructured, or custom documents.
Using Nanonets can bring in a host of benefits, including cost savings, enhanced compliance, and improved productivity. Here are some unique benefits that set Nanonets apart are:
- No coding required
- Works with all document types
- Custom AI models
- No post-processing or pre-processing is required.
- Handles multi-lingual documents
- Recognizes 200+ languages
- 1-day setup
- 5000+ integrations with API and Zapier
- 24x7 live support
- Transparent Pricing Options
- White label solution
- On-premise & Cloud Hosting
Here's a snapshot of the performance expected from Nanonets.

Nanonets is highly rated on peer-to-peer customer review websites as shown below.

See how you can automate your Document indexing process with Nanonets in 15 minutes.
Get a free product tour or try it yourself.
How to use Nanonets for document indexing?
Step 1: Create an account on Nanonets (Start for free now) and log in.
Step 2: Select the document classification model from the main screen.
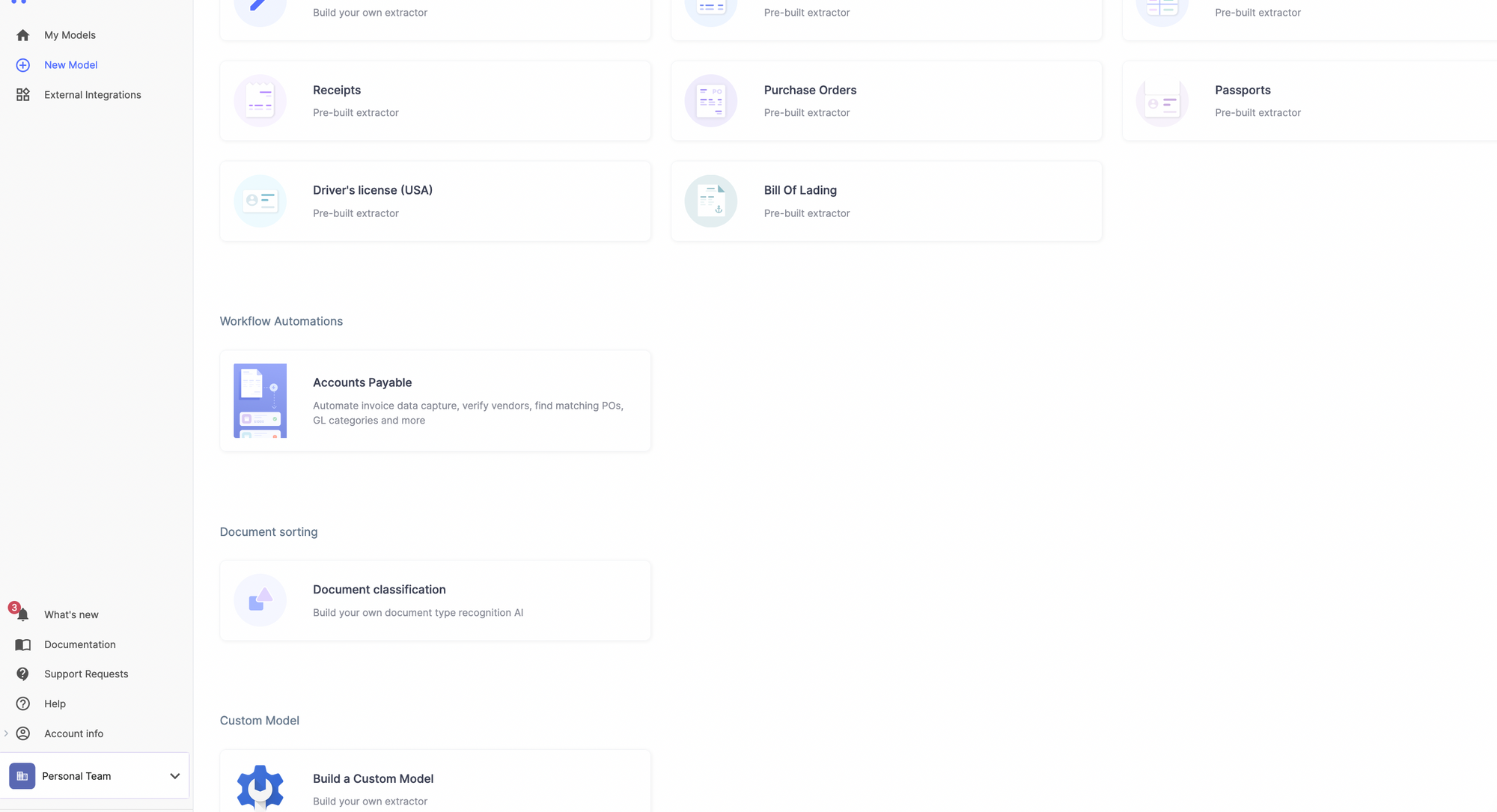
Step 3: Select the document tags that you’d like to include.

Step 4: The Nanonets AI algorithm needs only 25 documents to train the AI model to recognize your document type. Upload 25 documents for every document tag and let the model train.
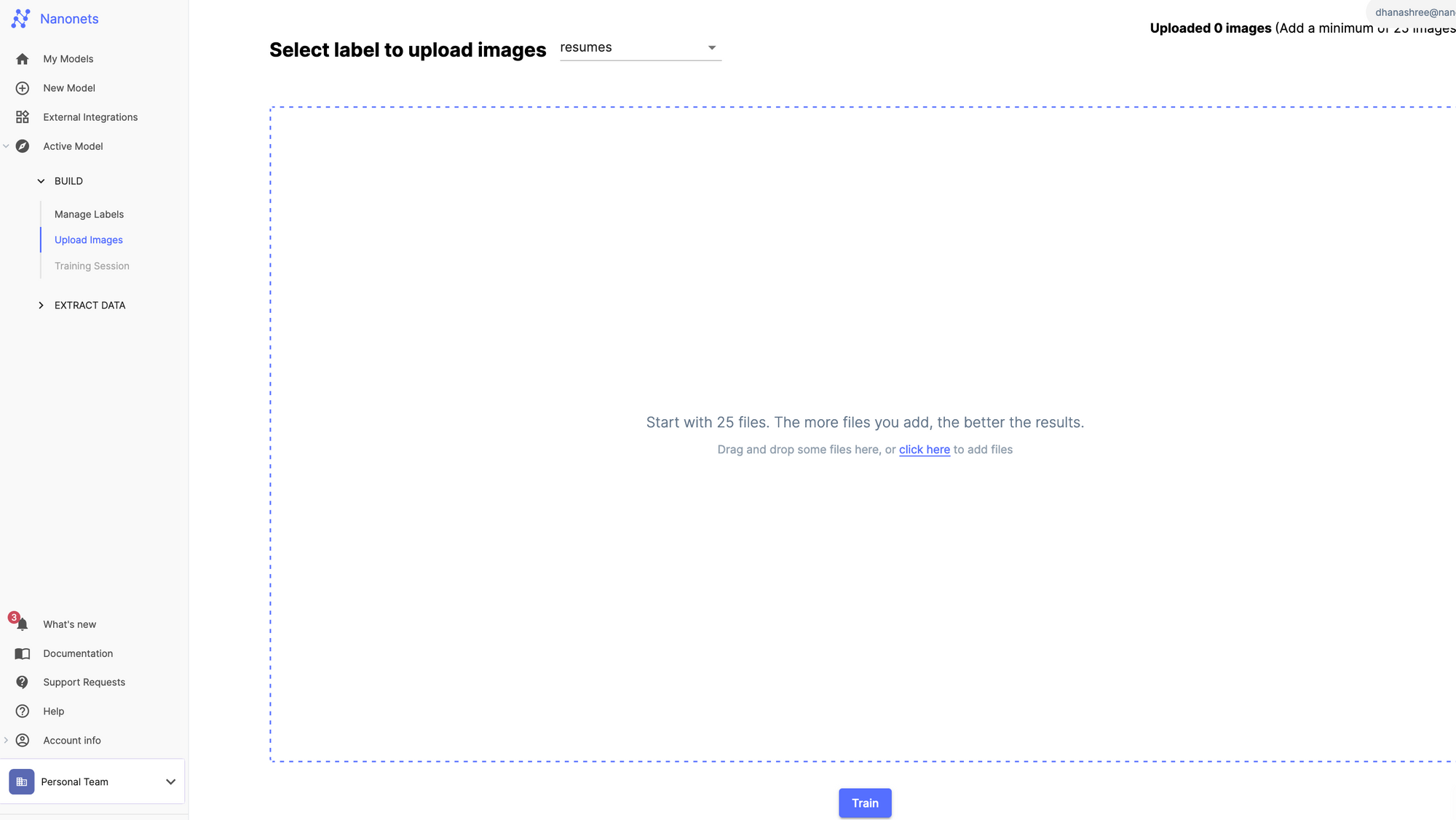
Step 5: Once done, you can use document workflow to automatically send documents, index them and send them to the database as required. You can use document workflows to extract data from documents, process documents, or send them through an approval process. Your imagination is the limitation.
Document indexing with Nanonets is easy.
Start your free trial and do it yourself. In case you need help, schedule a 10-minute call with our automation experts to let us set up workflows for you.
Get a free product tour or Start your free trial.
How does it Help You Find Documents?
Document indexing is a fundamental element of any business document management technique and is a tremendous way to build more efficient workflows. With adequate indexing, any document your workers need is simple to search for and retrieve with just a limited keystroke. But it can be complicated to implement powerful document indexing if you do not have adequate tools.
Conclusion
Document indexing is a powerful approach for helping later retrieval of documents from huge archives, including thousands of documents. Documents could be indexed by their full-text content (like any word in the data may be accessed) or by information related to the document, such as a day of production, a unique identifier, or the document’s central theme.
Read more about document management:
- How to automate document verification?
- Verify 10,000+ ID cards with automated ID verification
- How to archive documents properly?
- Which are the best legal document management software?
- How to classify documents using document workflows?
- Enhance document security with Nanonets
- Automate document indexing with no-code workflows
- The 2023 Guide to Document Automation
- Top EDMS systems in 2023
- The 2023 guide to document processing
FAQ
What is the Data used to Index Documents?
One significant decision to get the most out of the new digital files is to select what indexing standards to use. Some instances of data used for indexing include:
- Order number
- Addresses
- Dates
- First and last names
- Phone numbers
- Invoice number
- Customer numbers
- Account numbers
- Keyword descriptors
What Is the Purpose of Indexing?
The fundamental purpose of indexing is to have the capacity to quickly scan for and retrieve information included within your scanned papers. It can also enhance your office efficiency by enabling your workers to search for info without manually running through boxes of files.
What Are the Qualities of Good Indexing?
The end objective of an indexing project is to build a system where users can efficiently retrieve data. This is accomplished through:
- Affiliate with end users (department heads, managers, employees) to get their opinions.
- An easy system that is simple to use.
- Including a choice to search for particular fields on a document and full text.
- The involvement of skilled indexing professionals to help guide and advise you through the process.
How Does It Vary from One Industry to the Other?
One of the essential factors in selecting indexing terms is how documents will be surveyed. For instance, in a series of personnel files, mainly the first and last names and employment dates would be popular means of searching
Contrarily, medical certificates could reference parsing birth dates or insurance policy numbers. Including commonly used search terms during document indexing will give better results.
How Does Document Indexing Function?
Document indexing functions by attributing certain information to scanned documents, enabling efficient and fast retrieval. There are various methods for document indexing, each with its unique benefits.
What’s Your Best Document Indexing Option?
Document indexing creates the seamless search and retrieval of vast quantities of documents when applied appropriately. Nonetheless, the proper indexing procedure is not one-size-fits-all. Whether documents are indexed by their entire text, organized by areas, or supplemented with good metadata, this option drives the success of the whole system. A skilled partner can enable your team to select the proper indexing techniques that fit your team’s unique exercises.
Use a no-code platform to index all your documents on autopilot with no-code workflows. Interested?
Get a free product tour or Start your free trial.
8 February 2023: This blog was originally published in June 2022 and was updated ion 8 February 2023 with updated content.


