













































A complete guide on How to Extract Tables from PDF in Python
This blog serves as a starting point for anyone looking to extract tables from PDF files and images. We start with a python code tutorial which takes you through the process of implementing OCR on PDF files and images to detect and extract tables in structured formats (list, json object, pandas dataframe). We then take a look at a no code platform for automated tabular extraction, and then explore a few table extraction tools available for free online.
Introduction
The total number of PDF documents in the world is estimated to have crossed 3 trillion. The adoption of these documents can be attributed to their inherent nature of being independent of platforms, thus having a consistent and reliable rendering experience across environments.
There are many instances arising everyday where there is a need to read and extract text and tabular information from PDFs. People and organisations which traditionally did this manually have started looking at technological alternatives which can replace manual effort using AI.
OCR stands for Optical Character Recognition, and employs AI to convert an image of printed or handwritten text into machine readable text. There are various open-source and closed-source OCR Engines existing today. It should be noted that often times, the job is not complete after OCR has read the document and given an output consisting of a stream of text, and layers of technology are built over it to use the now machine readable text and extract relevant attributes in a structured format.
Python Code - Extract Tables from PDF
We will use the below invoice for table extraction. The goal is to read the quantity, description, unit price, amount of each product in the PDF of the invoice in tabular format.
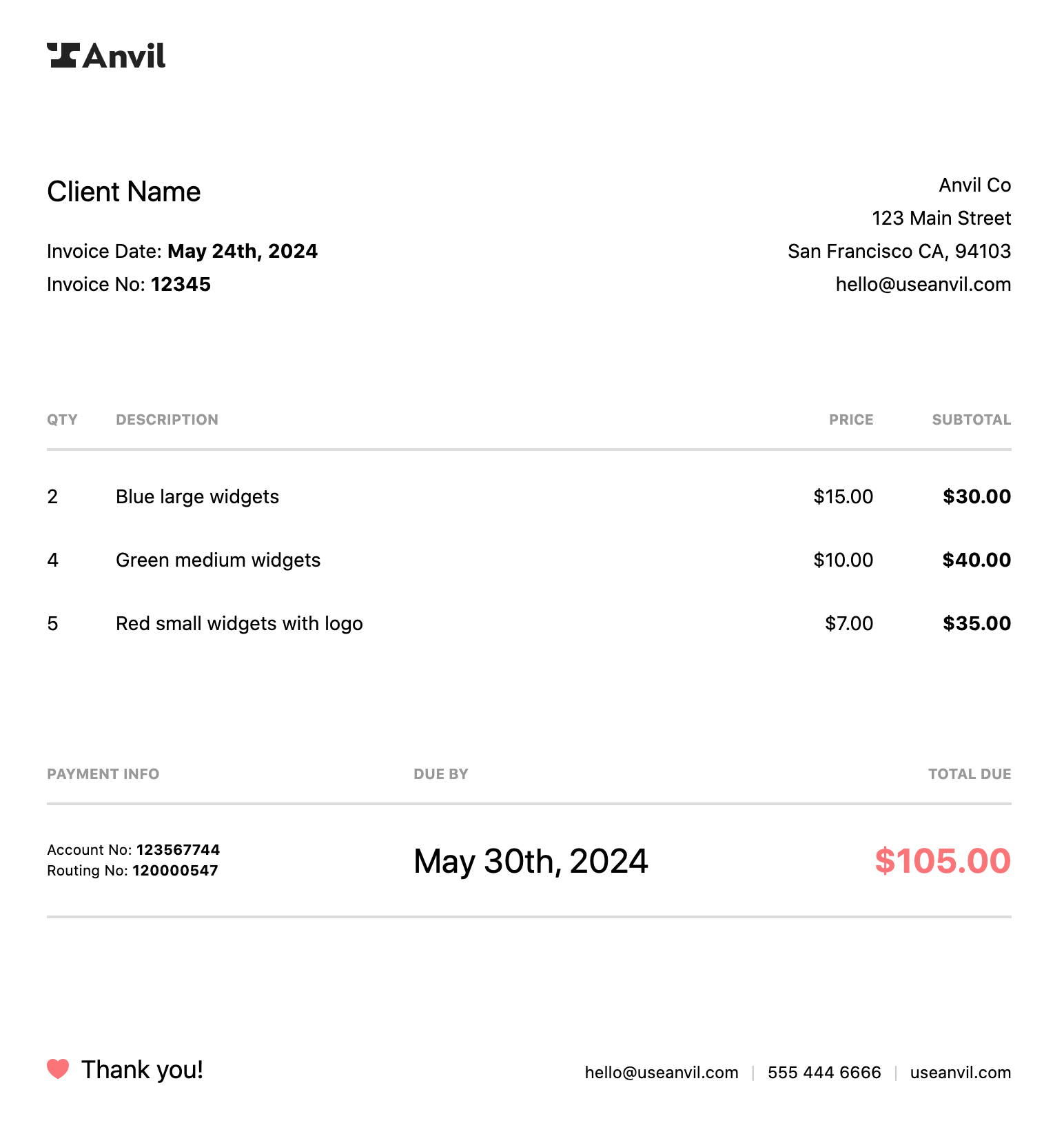
Let us get started.
Prerequisites
The OCR required to process the file and extract the table is handled by an API call to Nanonets API.
To make the API call and get extracted tables from pdf, we need the requests library. For the postprocessing code which transforms the API response into list of dataframes, we need the pandas and numpy library. You can install them into your Python environment by using pip.
pip install requests pandas numpy
Extract Tables from PDF File
To get your first prediction, run the code snippet below. You have to add your API_KEY and MODEL_ID to authenticate yourself.
You can get your free API_KEY and MODEL_ID by signing up on https://app.nanonets.com/#/signup?redirect=tools.
Once done, run below code snippet.
import requests
url = 'https://app.nanonets.com/api/v2/OCR/Model/REPLACE_MODEL_ID/LabelFile/?async=false'
data = {'file': open('invoice.png', 'rb')}
response = requests.post(url, auth=requests.auth.HTTPBasicAuth('REPLACE_API_KEY', ''), files=data)
We get the below output.
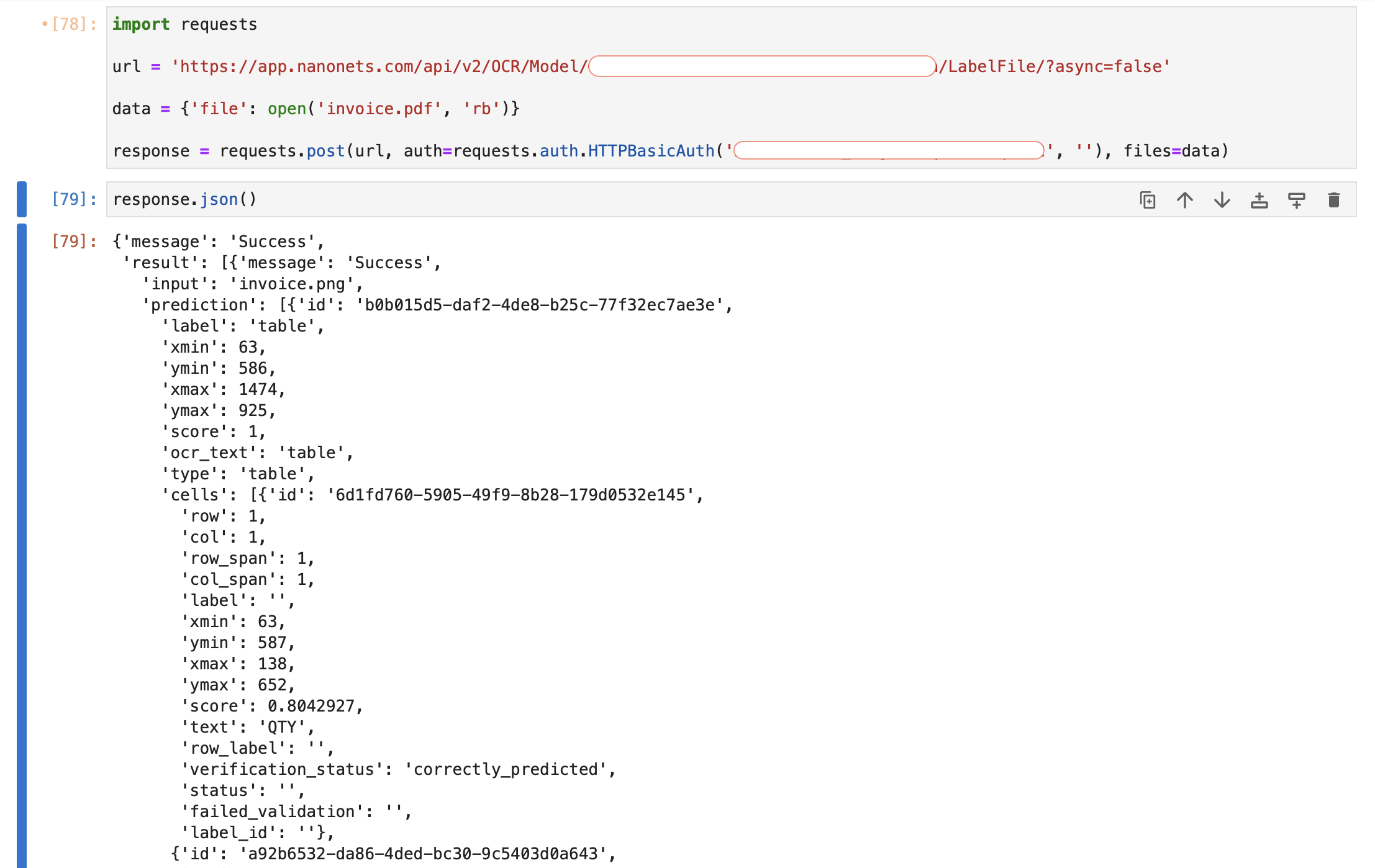
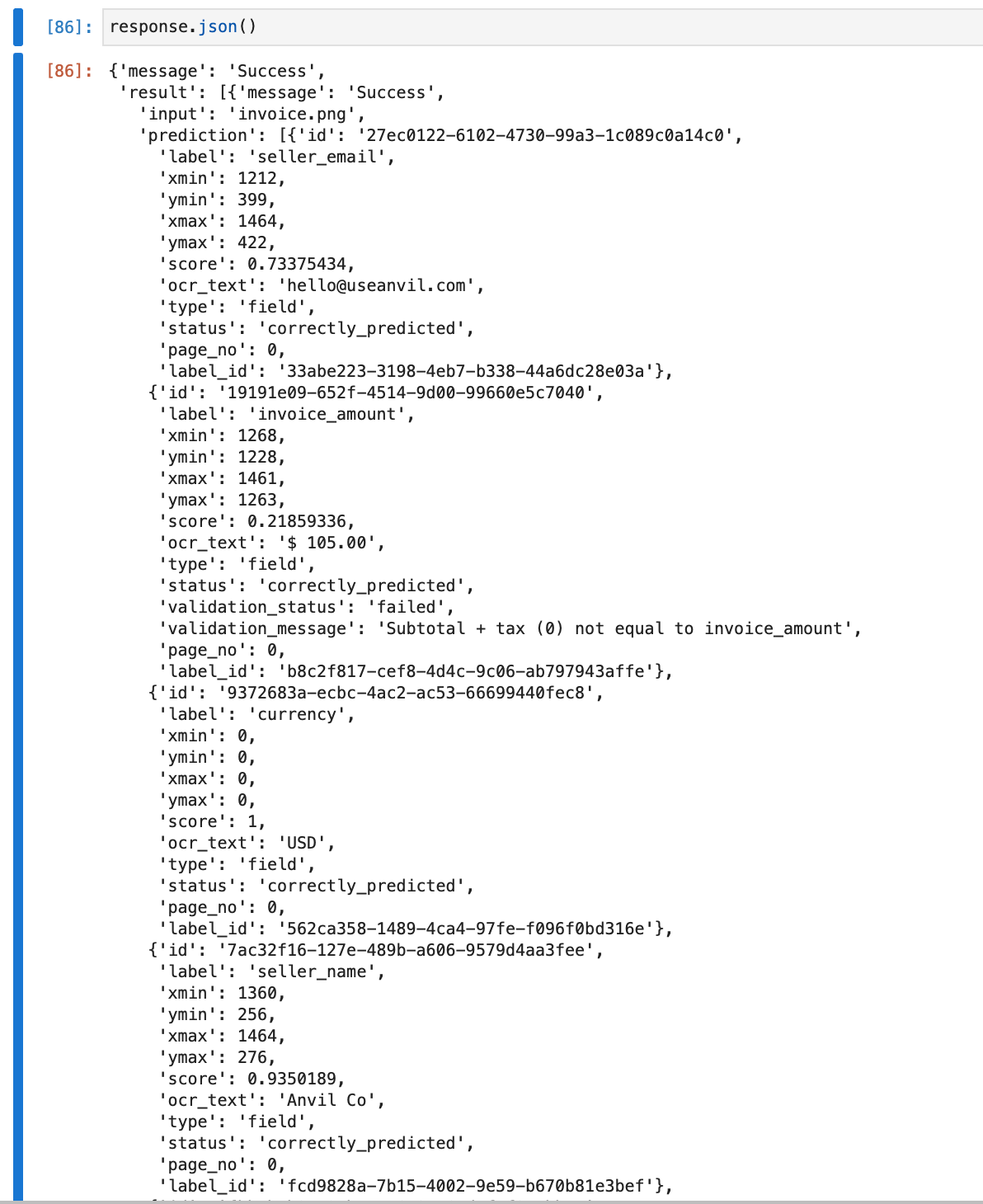
The result object contains an array of page wise result objects. Each object contains the prediction object having all detected tables as array elements. Each detected table then has an array called cells, which is an array of all cells of the detected table. The row, column and detected original text is present as row, col, ocr_text attribute of each cell object in cells.
We will now perform some post processing to transform the json response into pandas dataframes. After getting the API response above, you can run the code snippet below to get a list of dataframes containing the detected tables.
import pandas as pd
import numpy as np
alldfs = []
for item in response.json()["result"]:
tables = []
dfs = []
for pred in item['prediction']:
if pred['type'] == 'table':
labels = ['none'] * 100
maxcol = 0
for cell in pred['cells']:
if labels[cell['col'] - 1] == 'none':
labels[cell['col'] - 1] = cell['label']
if cell['col'] > maxcol:
maxcol = cell['col']
labels = labels[:maxcol]
df = pd.DataFrame(index=np.arange(100), columns=np.arange(100))
for cell in pred['cells']:
df[cell['col']][cell['row']] = cell['text']
df=df.dropna(axis=0,how='all')
df=df.dropna(axis=1,how='all')
df.columns = labels
tables.append(df)
alldfs.append(tables)
After running this, the alldfs object is a list where each object of the list contains predictions for each page of the document. Furthermore, each such object is itself a list of dataframes containing all tables on that page.
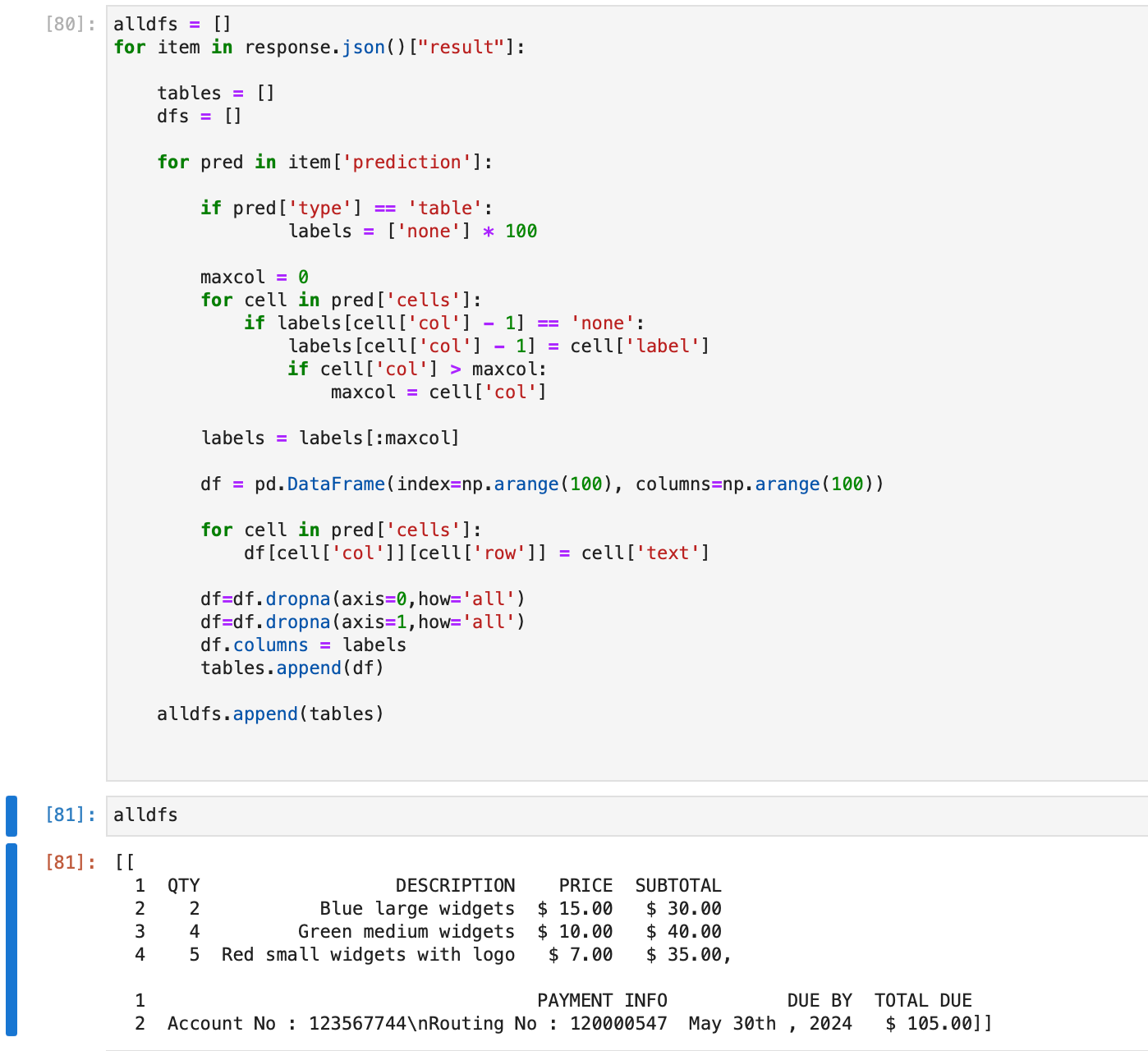
We can see that the two tables present on the invoice pdf have been detected and stored as dataframes on the first page alldfs[0], and the two tables can be accessed at alldfs[0][0] and alldfs[0][1].
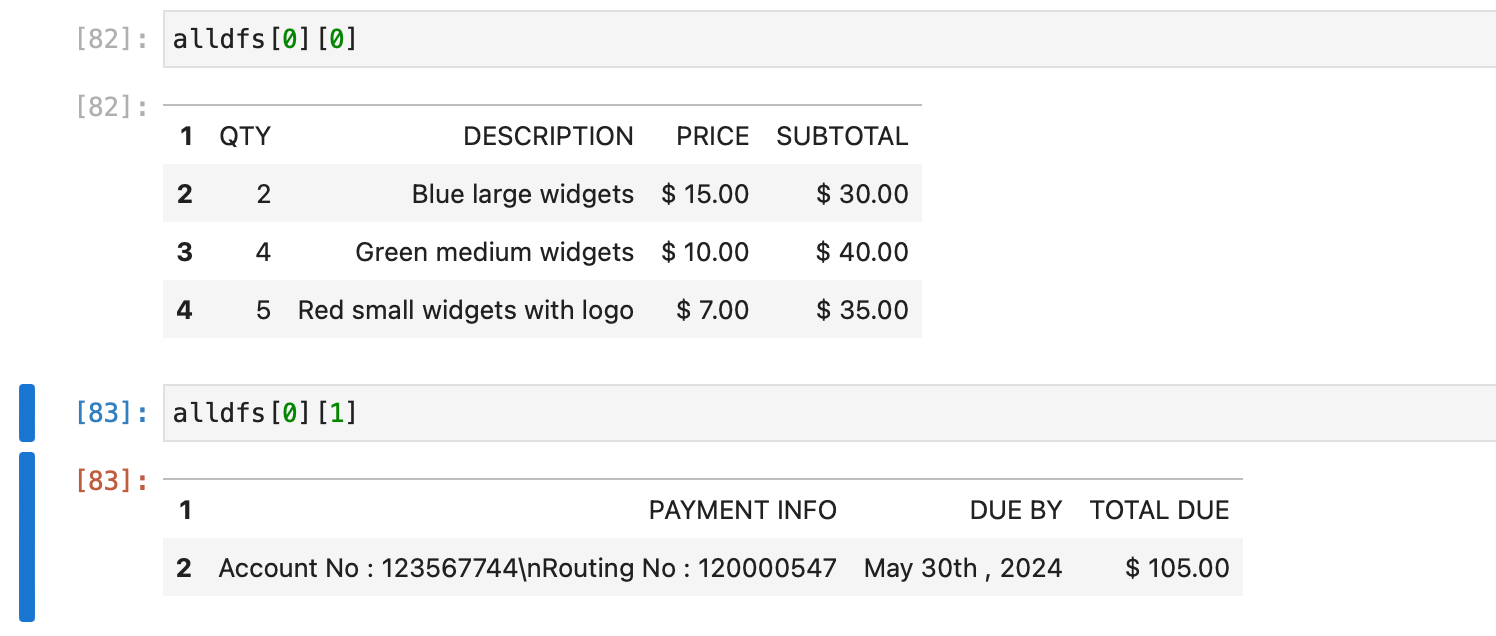
Thus, we have performed OCR on our first PDF file and extracted tables from it. We examined the json response and performed postprocessing using pandas and numpy to get data in desired format. You can also apply your own postprocessing to process and use data from the json response according to your use case.
We also provide a no code platform along with the Nanoents API with added support for line items, automated imports and exports from popular ERPs / software / databases, framework for setting up approval and validation rules, and much more.
One of our AI experts can get on a 15-min call to discuss your use case, give you a personalized demo and find the best plan for you.
Do More - Extract Line Items and Flat Fields
You can extend the functionality of the Nanonets OCR to detect flat fields and line items along with tables from pdf files and images. You can train your own custom model in 15 minutes to detect any line item or flat field in an image or a pdf file. Nanonets also offers prebuilt models with line item support added for popular document types such as invoices, receipts, driving licenses, ID cards, resumes etc.
Thus, creating a custom model or using one of our prebuilt models allows you to detect and extract line items, flat fields and tables in a single API call.
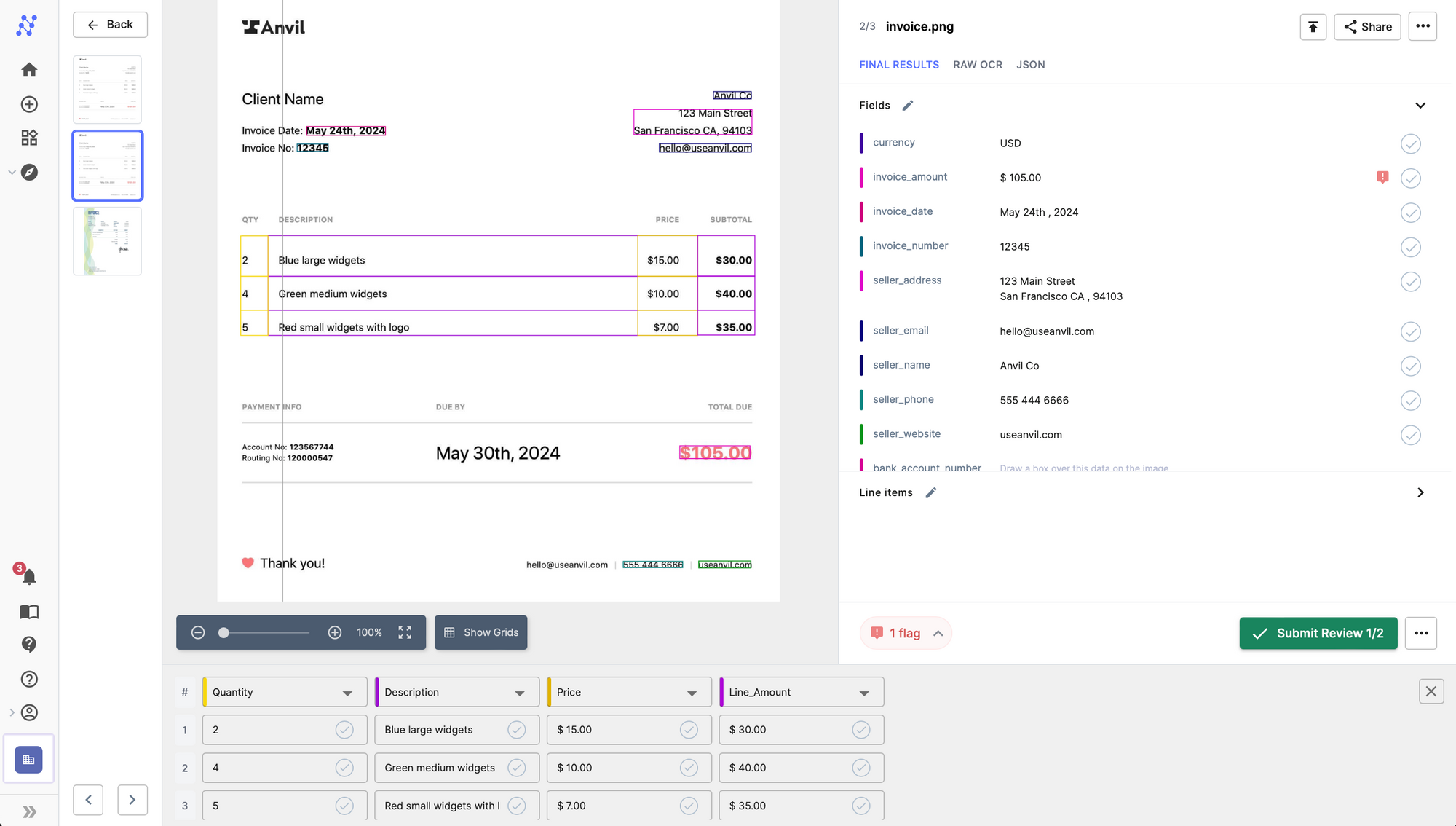
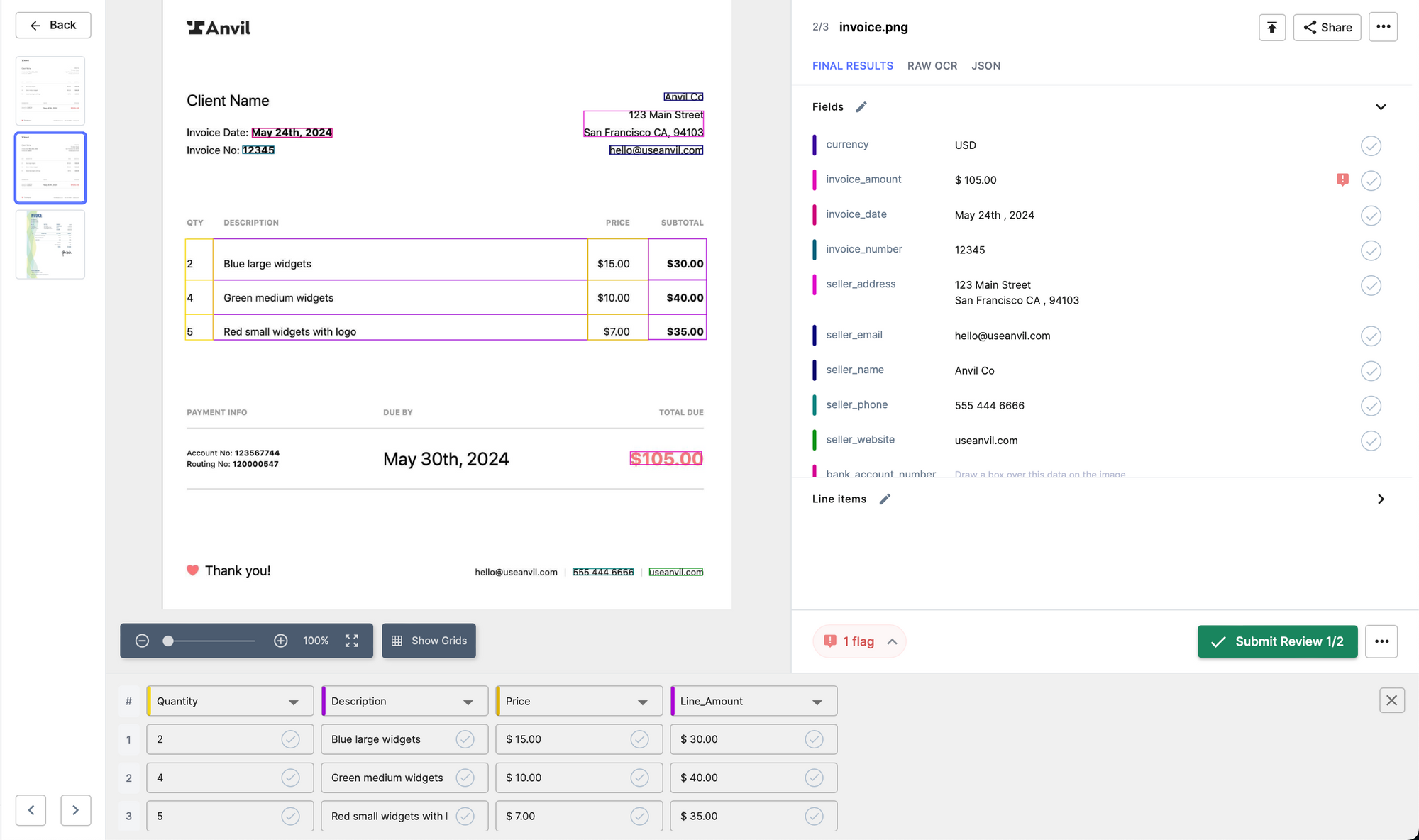
Let us take the example of the invoice above. The goal now is to detect flat fields like seller name, seller address, phone number, email, total amount along with the tables from the invoice pdf file using Nanonets OCR.
You can go to https://app.nanonets.com and clone the pretrained invoice document type model.
Once done, navigate towards the Integrate section on the left navigation pane, which gives ready to use code snippets to extract line items, flat fields and tables using the Nanonets API.
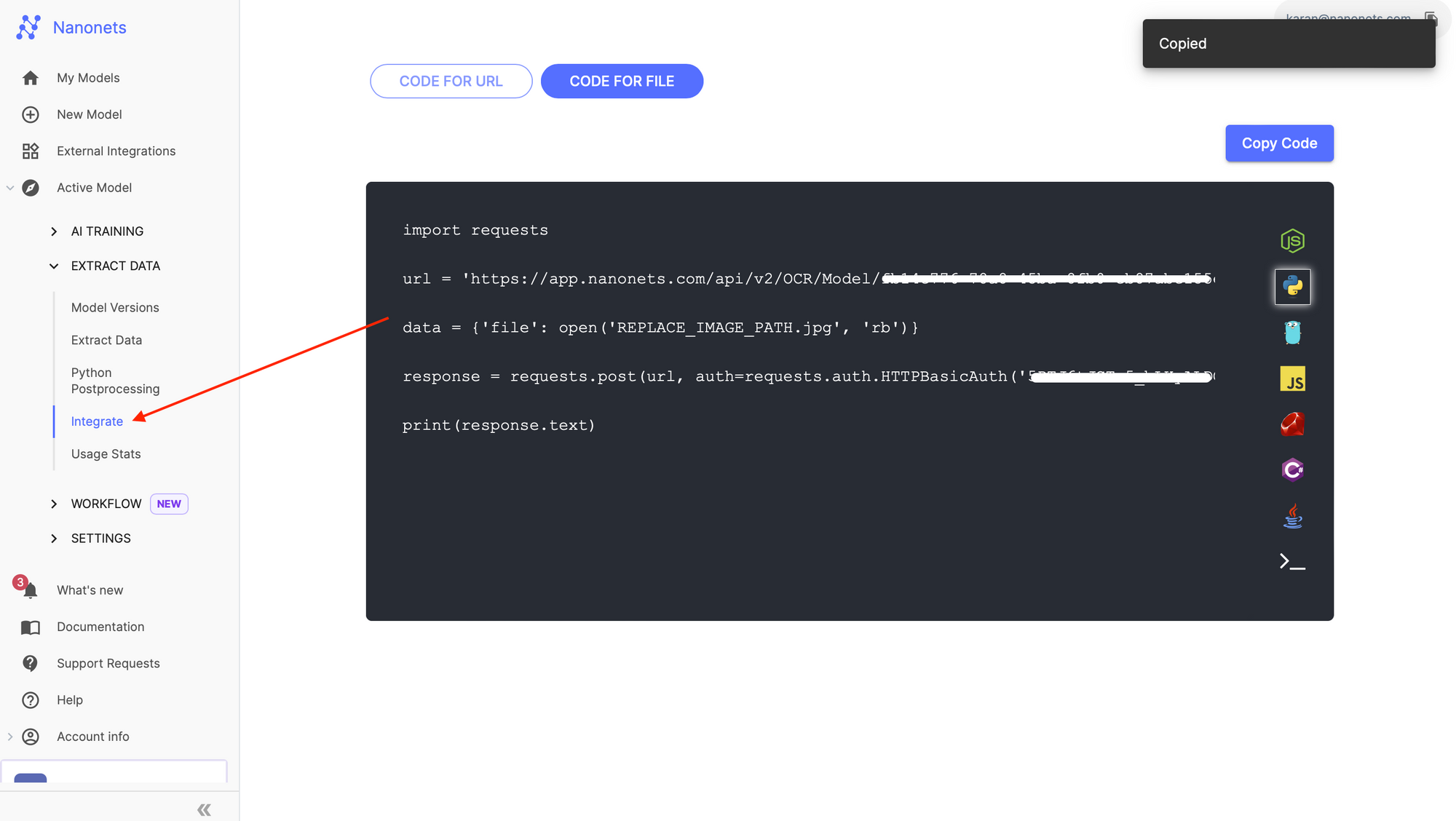
Running the code snippet above on our invoice file, we can detect line items along with tables in the API call.
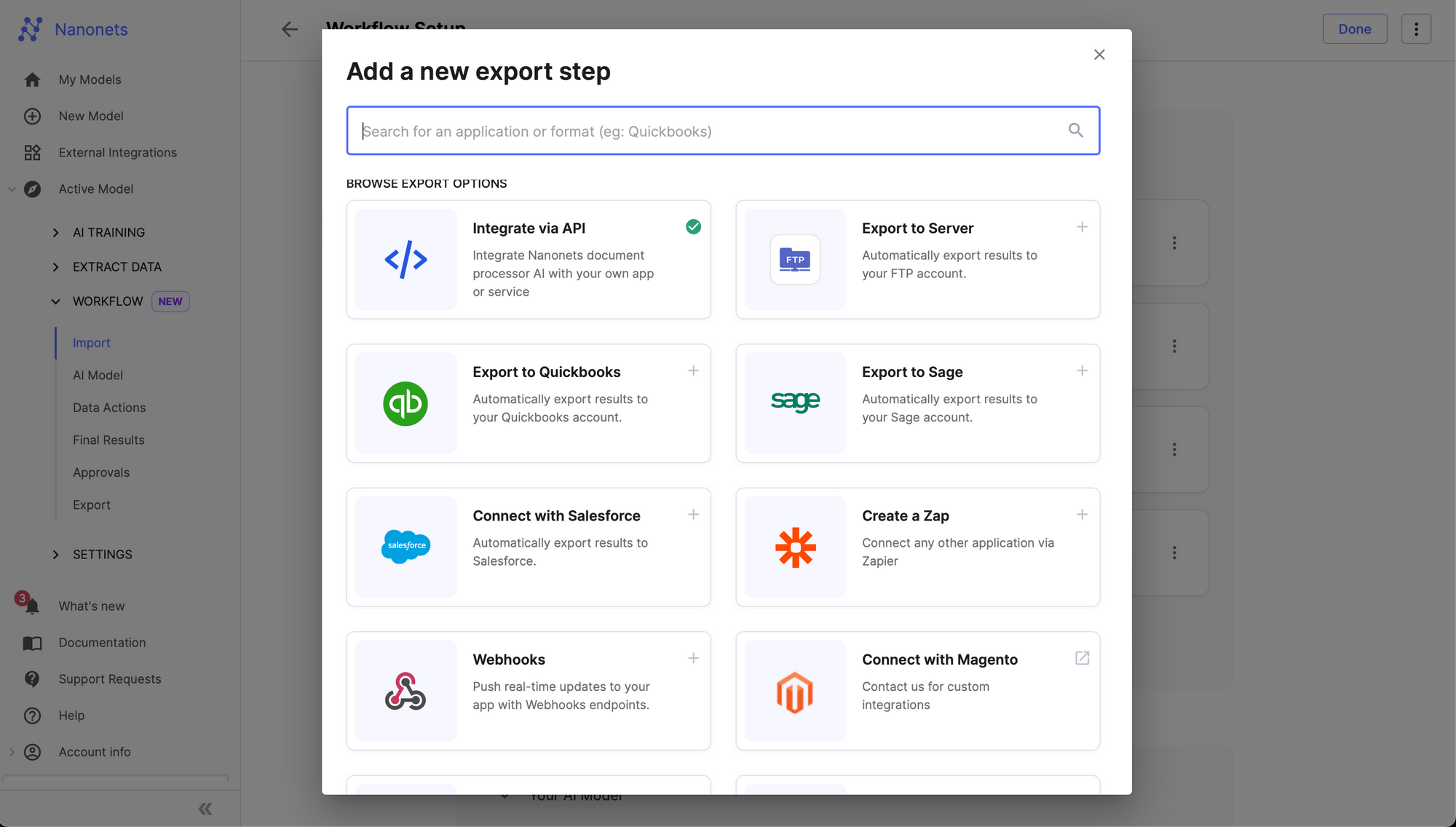
You can also use our online platform to set up an automated workflow and extract line items and tables from PDF files and images, configure external integrations with popular ERP / software / databases and set up approval and validation rules.
One of our AI experts can get on a 15-min call to discuss your use case, give you a personalized demo and find the best plan for you.
Table Extraction on Nanonets
We offer table extraction on our online platform as well as through the Nanonets API. Once your Nanonets account is up and running, you can choose to use the platform instead of the API to extract tables from your documents.
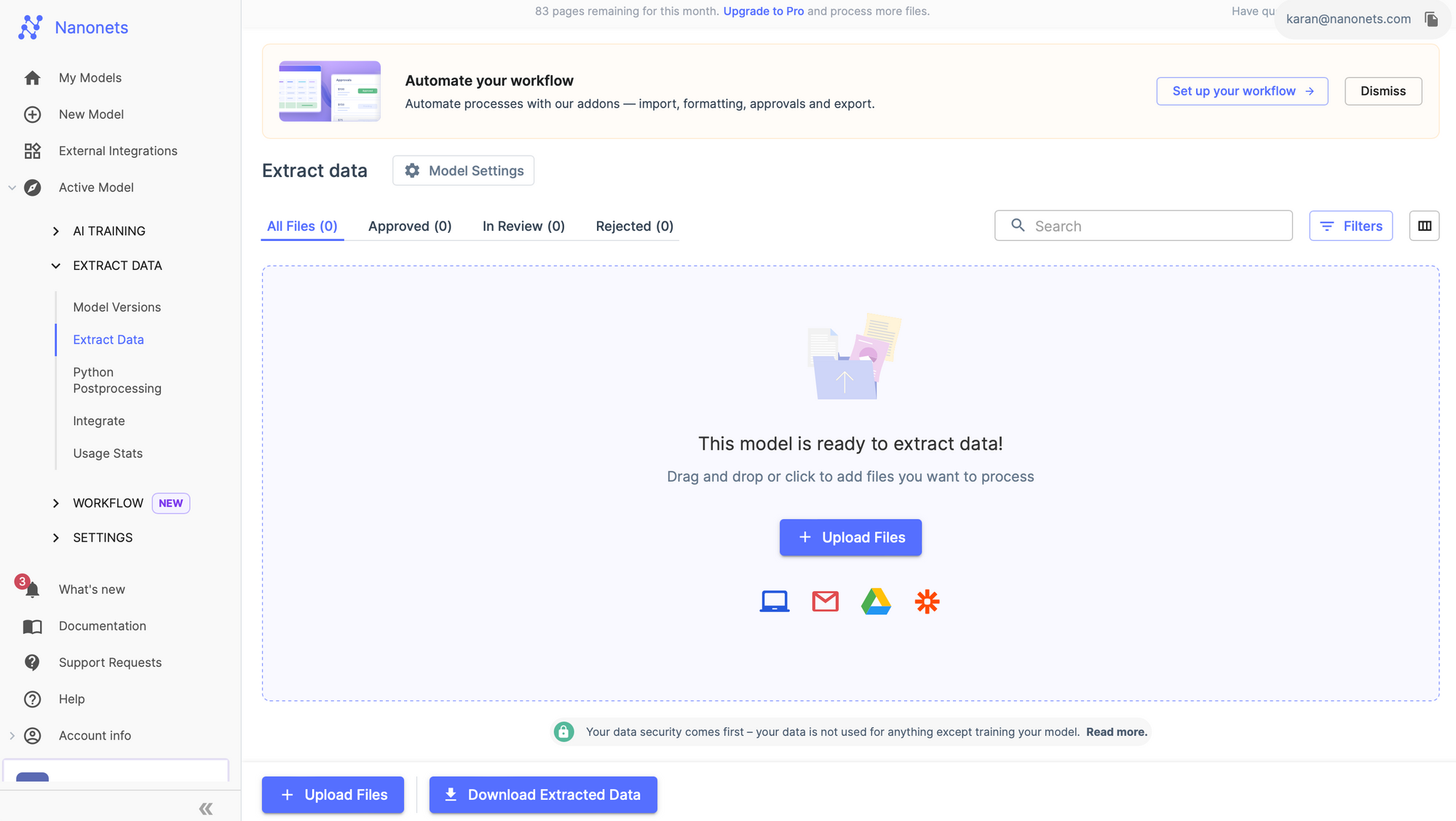
You can configure your workflow here. We offer readymade integrations with multiple popular ERP / software / databases.
- automated imports and exports to ERP / software / database
- set up automated approval and validation rules
- configure postprocessing after extraction
One of our AI experts can get on a 15-min call to discuss your use case, give you a personalized demo and find the best plan for you.
Online Free Table Extraction Tools
There are a bunch of free online OCR tools which can be used for performing OCR and extracting tables online. It simply is a matter of uploading your input files, waiting for the tool to process and give output, and then downloading the output in required format.
Here is a list of free online OCR Tools that we provide -
Have an enterprise OCR / Intelligent Document Processing use case ? Try Nanonets
We provide OCR and IDP solutions customised for various use cases - accounts payable automation, invoice automation, accounts receivable automation, Receipt / ID Card / DL / Passport OCR, accounting software integrations, BPO Automation, Table Extraction, PDF Extraction and many more. Explore our Products and Solutions using the dropdowns at the top right of the page.
For example, assume you have a large number of invoices that are generated every day. With Nanonets, you can upload these images and teach your own model what to look for. For eg: In invoices, you can build a model to extract the product names and prices. Once your annotations are done and your model is built, integrating it is as easy as copying 2 lines of code.
Here are a few reasons you should consider using Nanonets -
- Nanonets makes it easy to extract text, structure the relevant data into the fields required and discard the irrelevant data extracted from the image.
- Works well with several languages
- Performs well on text in the wild
- Train on your own data to make it work for your use-case
- Nanonets OCR API allows you to re-train your models with new data with ease, so you can automate your operations anywhere faster.
- No in-house team of developers required
Visit Nanonets for enterprise OCR and IDP solutions.
Sign up to start a free trial.


