













































A complete Guide to Named Entity Recognition (NER) in 2024
Have a NER problem in mind? Want to leverage NLP along with OCR & NER to automate information extraction?
The rate at which we generate information has been growing for years, especially text-based data like documents and reports. Using this data, we were able to generate many valuable insights and predictions with powerful algorithms.
However, building these algorithms or computer programs from scratch requires extensive expertise and experimenting, especially for information extraction from text-based data. Hence we rely on NLP (Natural Language Processing) techniques like Named Entity Recognition (NER) to identify and extract the essential entities from any text-based documents.

In this guide, we'll be deep-diving into NER and its brief history. We'll also look at some of the state-of-the-art models you directly use for your documents and learn how to build one with modern frameworks and libraries.
Table of Contents
- What is Named Entity Recognition?
- Use Cases of Named Entity Recognition
- How to Build or Train NER Model
- Performing NER with NLTK and Spacy
- NER Business Example
- Using Nanonets
- Conclusion
What is Named Entity Recognition?
The term Named Entity was first proposed at the Message Understanding Conference (MUC-6) to identify names of organisations, people and geographic locations in the text, currency, time, and percentage expressions. Since then, there has been increasing interest in NER and Information Extraction (IE) techniques on text-based data for various scientific events.
Today, NER is widely used across various fields and sectors to automate the information extraction process.
Named entity recognition (NER) is an NLP based technique to identify mentions of rigid designators from text belonging to particular semantic types such as a person, location, organisation etc.
Below is an screenshot of how a NER algorithm can highlight and extract particular entities from a given text document:

As we can see from the above image, we can identify names of people, dates, organisations etc.
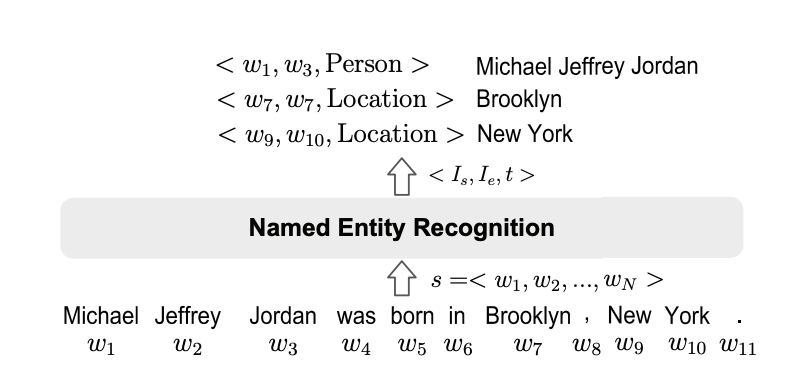
Building a highly accurate NER algorithm requires a vast understanding of math, machine learning & image processing. Alternatively, using popular frameworks like PyTorch and Tensorflow and a few pre-trained models, we can build a Named Entity Recognition algorithm from custom data.
Use Cases of Named Entity Recognition
As discussed, NER helps us to identify and extract critical elements from text data, such as names of people, geographical location, organisation, monetary values, and more. This helps a lot of businesses and organisations to find insights on large unstructured datasets. Now let’s review some of the everyday use cases where NER can be of utmost help.
Support Chatbots
Managing support for online businesses is hard. Hence setting up support bots that can automate document collection, reviews and refund pipelines could help save manual work and human effort.
There are a few challenges here, and the bots can't be conditioned based on customers' responses. First, they should understand who they are talking to and identify specific information such as invoice id, delivery time, taxes etc. Next, based on the extracted data, they should send responses to customers or send a notification to support managers to escalate issues.
This can only be achieved if the bots are intelligently trained with NER algorithms to identify entities from the chat and process data appropriately. Also, the extracted information from these NER (named entity recognition) models can be further used to retrain the same algorithm to achieve higher levels of accuracy.
NER for Medical Purposes
Extracting valuable information from biomedical literature has gained popularity among researchers. Furthermore, deep learning has boosted the development of effective biomedical text mining models. Thanks to NER and Information Extraction, we can now easily identify important terms in medical reports.
Say a hospital treats X number of patients & generates Y number of reports every day. A named entity recognition algorithm could determine the quantity and types of drugs required to treat these patients. The algorithm can also recognise & match demographic factors that could provide analysts/doctors deeper insights.
Document Categorisation
Say you're working on large document datasets, like news reports or sports articles and want to search for a particular report. In these cases, NER could classify all the information appropriately. Additionally, NER could extract a few entities and then classify these reports into various classes. This could save a lot of time and boost the efficiency of teams.
Have an OCR problem in mind? Want to digitize invoices, PDFs or number plates? Head over to Nanonets and build OCR models for free!
How to Build or Train NER Model
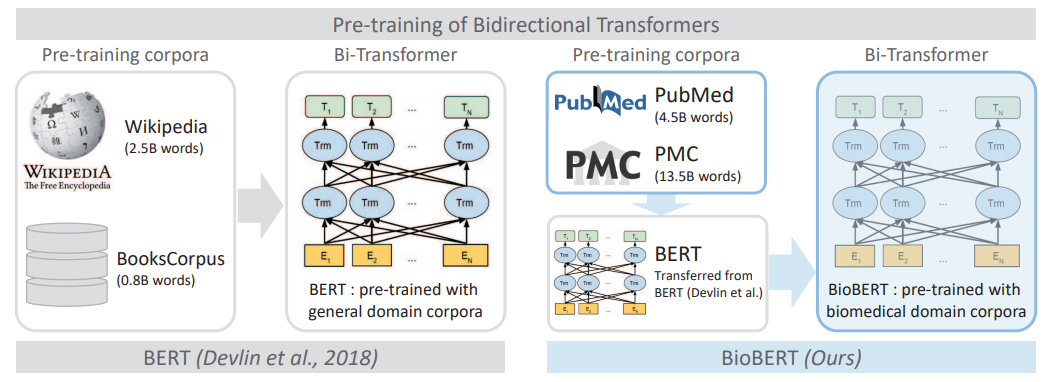
Now, let's look at a common approach to building a Named Entity Recognition Model. We'll be using a language model called Bidirectional Encoder Representations from Transformers (BERT) to explain the steps involved in training state of the art NER models.
Inspired by ELMO and GPT pre-trained models, BERT uses a bidirectional training of transformer to the language model. With this, we can understand text patterns to analyse context and meaning. Using BERT for building a NER is very straightforward; we can download any pre-trained model, fine-tune it and update the pre-trained model to fit downstream tasks. Now, let's look at the steps in detail.
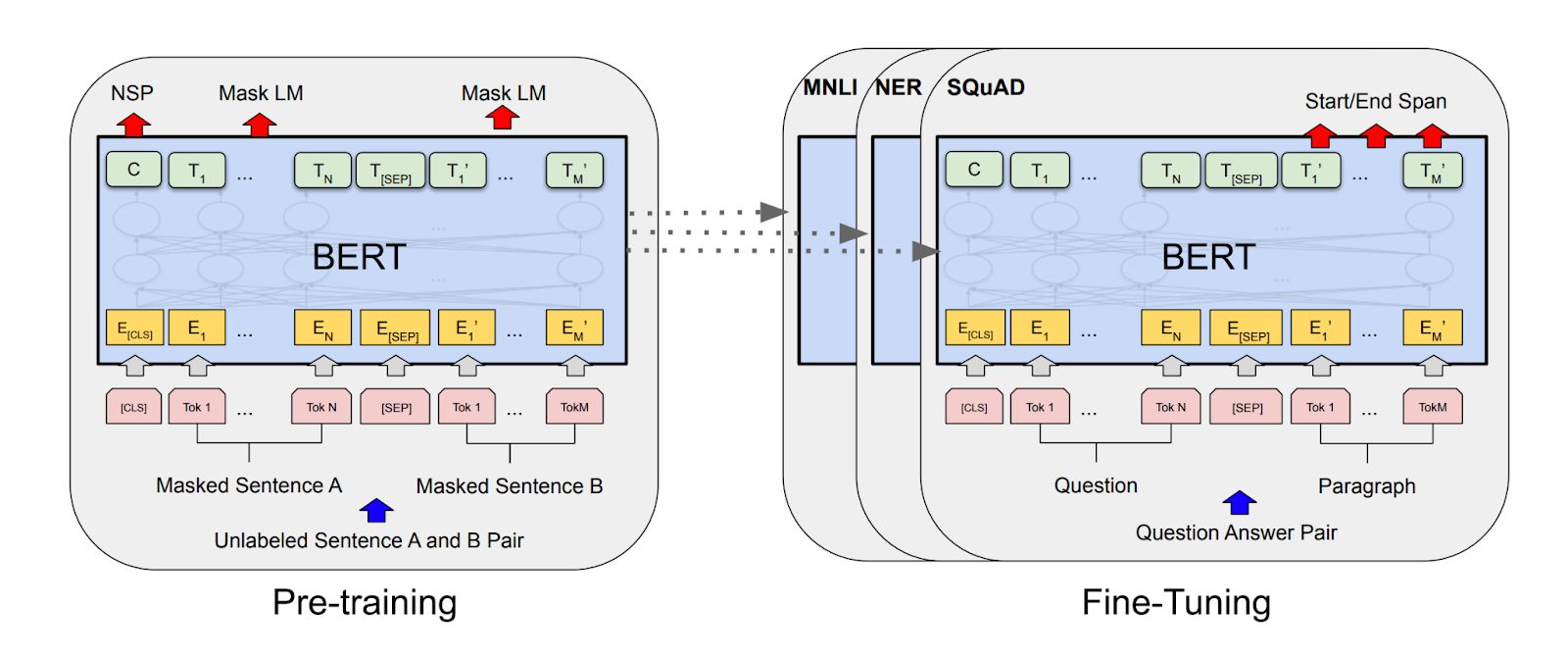
Step #1: Data Acquisition
The first step in training any deep-learning-based model is to process the data. Now for our NER, we'll be doing the same. We can either leverage any annotated/labelled data or build one from scratch based on our use case. In terms of the number of annotations, for a custom entity type, say medical terms or financial terms, we can, in some instances, get good results with as little as 300 annotated examples.
One advantage of using the BERT language model is that we can train it not just on particular sentences containing the entity of interest but also on the entities themselves. For instance, for a person tagger, we can train the model on just the names of persons alone in addition to their mention in sentences. Since BERT produces words using subwords, we can leverage the knowledge from single entity mentions generalising to other entity instances that share the same subwords.
Step #2: Input Preparation to fine-tune the Model
Unlike training traditional NLP models, NER uses a specific tagging scheme. This is because we'll need to train named entities rather than individual words. Alternately of tokens referring only to classes, such as "name" "location". They are prefixed with the information where a phrase like "B" or "I" stands for "beginning" and "inside."
For example, consider the name "Steve Jobs' '; this would be tagged as (B-PER, I-PER), meaning (person, person). This technique is known as the IOB (sometimes BLUE) format. However, we need not build special classes for these. If we find this difficult, we can directly use some popular frameworks like TensorFlow or and utilise the pre-processor classes to perform the tagging.
Additionally, a few things should also be taken care of, such as case sensitivity, special characters and spacing of words, and turning the first letter of every uppercase letter. These small things will lead to higher accuracies and make the model more generic for other datasets. We can achieve this by using POS tagger and then using tags such as NN and NNP to define each word's parts.
Step #3: Initialise Pre-trained Model, Hyper-parameter Tuning
In step three, we'll be loading the BERT model onto the program and initialising the hyperparameters like any other deep learning algorithm. However, finding the proper parameters right at the start might be difficult. You can fine-tune it based on how the model is performing on your data. For references, you can find the more fine-tuned model from the transformers' repo for NER. Another organisation named Hugging Face has a lot of scripts to use as new Trainer models.
Also, in this step, we'll need to load the labelled data as tensors for training them on a deep neural net.
Step #4: Training BERT Model and Predictions
The training process is straightforward just like any other deep learning network. We'll first write a loop based on the number of epochs and check for GPUs; if so, we move the model over to it for training. Then we activate training parameters in our model and initialise a loss function and optimiser.
Step #5: Estimating Accuracy of NER Model
We can estimate the performance of a NER model in different ways. Usually, this is done by calculating the F1 score or relaxed match:
- F1 Score: The proportion of the number of shared words to the whole number of words in the prediction, and recall is the proportion of the number of shared words to the total number of words in the ground truth. (Source: Wikipedia)
- Relaxed Match: We can estimate "relaxed match" by calculating performance based on the proportion of entity tokens identified as the correct entity type, regardless of whether the "boundaries" around the entity were correct.
For example, for a partial match: Say a model classifies "United States of America" as [B-LOC] [I-LOC] [O] [B-LOC], where the correct labels are [B-LOC] [I-LOC] [I-LOC] [I-LOC]. This would receive 75% credit rather than 50% credit. The last two tags are both "wrong" in a strict classification label sense, but the model at least classified the fourth token as the correct entity type.
Awesome, we’ve learned how to train a NER model from scratch. Now let’s actually dive into popular libraries and perform NER on simple sentences.
Performing NER with NLTK and Spacy
In this section, we’ll be using some of the most loved NLP frameworks for performing Named Entity Recognition and Information Extraction on text documents.
NER with nltk
nltk is a leading python-based library for performing NLP tasks such as preprocessing text data, modelling data, parts of speech tagging, evaluating models and more. It can be widely used across operating systems and is simple in terms of additional configurations. Now, lets install nltk and perform NER on a simple sentence.
To use the following scripts, make sure you’ve installed the stable python3, pip and nltk packages.
# Step One: Import nltk and download necessary packages
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')
nltk.download('words')
# Step Two: Load Data
sentence = "WASHINGTON -- In the wake of a string of abuses by New York police officers in the 1990s, Loretta E. Lynch, the top federal prosecutor in Brooklyn, spoke forcefully about the pain of a broken trust that African-Americans felt and said the responsibility for repairing generations of miscommunication and mistrust fell to law enforcement."
# Step Three: Tokenise, find parts of speech and chunk words
for sent in nltk.sent_tokenize(sentence):
for chunk in nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent))):
if hasattr(chunk, 'label'):
print(chunk.label(), ' '.join(c[0] for c in chunk))Output:
GPE WASHINGTON
GPE New York
PERSON Loretta E. Lynch
GPE BrooklynIf you observe the above output, the NER found a total of four entities, a name and three geographical locations, which is super cool with just four lines of python code. Let's decode what has happened.
Steps one and two are straightforward; we've imported the nltk package, downloaded all the necessary modules and defined the sentence as a python variable.
In step three, first, we return a sentence-tokenised copy of the text using nltk.sent_tokenize(sentence) and iterate over it.
code : nltk.sent_tokenize(sentence)
output:
['WASHINGTON -- In the wake of a string of abuses by New York police officers in the 1990s, Loretta E. Lynch, the top federal prosecutor in Brooklyn, spoke forcefully about the pain of a broken trust that African-Americans felt and said the responsibility for repairing generations of miscommunication and mistrust fell to law enforcement.']
Next, we tokenise the sentence and find parts of speech of each word; we’ll run nltk.pos_tag(nltk.word_tokenize(sent)) individually to see the outputs:
- Tokenising Words using
nltk: Tokenises the sentences into the list of words
code : nltk.word_tokenize(sent)
output:
['WASHINGTON', '--', 'In', 'the', 'wake', 'of', 'a', 'string', 'of', 'abuses', 'by', 'New', 'York', 'police', 'officers', 'in', 'the', '1990s', ',', 'Loretta', 'E.', 'Lynch', ',', 'the', 'top', 'federal', 'prosecutor', 'in', 'Brooklyn', ',', 'spoke', 'forcefully', 'about', 'the', 'pain', 'of', 'a', 'broken', 'trust', 'that', 'African-Americans', 'felt', 'and', 'said', 'the', 'responsibility', 'for', 'repairing', 'generations', 'of', 'miscommunication', 'and', 'mistrust', 'fell', 'to', 'law', 'enforcement', '.'] ]- POS tagging using
nltk: Identifies parts of speech of each word and returns an array of tuples with the words and their parts of speech.
code : nltk.pos_tag(nltk.word_tokenize(sent))
[('WASHINGTON', 'NNP'),('--', ':'),('In', 'IN'),('the', 'DT'),('wake', 'NN'),('of', 'IN'),('a', 'DT'),('string', 'NN'),('of', 'IN'),('abuses', 'NNS'),('by', 'IN'),('New', 'NNP'),('York', 'NNP'),('police', 'NN'),('officers', 'NNS'),('in', 'IN'),('the', 'DT'),
('1990s', 'CD'),(',', ','),('Loretta', 'NNP'),('E.', 'NNP'),('Lynch', 'NNP'),(',', ','),('the', 'DT'),('top', 'JJ'),('federal', 'JJ'),('prosecutor', 'NN'),('in', 'IN'),
('Brooklyn', 'NNP'),(',', ','),('spoke', 'VBD'),('forcefully', 'RB'),('about', 'IN'),('the', 'DT'),('pain', 'NN'),('of', 'IN'),('a', 'DT'),('broken', 'JJ'),('trust', 'NN'),('that', 'IN'),('African-Americans', 'NNP'),('felt', 'VBD'),('and', 'CC'),('said', 'VBD'),('the', 'DT'),('responsibility', 'NN'),('for', 'IN'),('repairing', 'VBG'),('generations', 'NNS'),('of', 'IN'),('miscommunication', 'NN'),('and', 'CC'),('mistrust', 'NN'),('fell', 'VBD'),('to', 'TO'),('law', 'NN'),('enforcement', 'NN'),
('.', '.')]
- Chunking on POS: Lastly, we perform a chunking operation that returns a nested
nltk.tree.Tree object so that we can iterate or traverse the Tree object to get to the named entities.
Finally, we get to the output if there is any entity label in the chunk:
for sent in nltk.sent_tokenize(sentence):
for chunk in nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent))):
if hasattr(chunk, 'label'):
print(chunk.label(), ' '.join(c[0] for c in chunk))GPE WASHINGTON
GPE New York
PERSON Loretta E. Lynch
GPE BrooklynNER with Spacy
Spacy is an open-source NLP library for advanced Natural Language Processing in Python and Cython. It's well maintained and has over 20K stars on Github. There are several pre-trained models in Spacy that you can use directly on your data for tasks like NER, Information Extraction etc. Now, let's look at a few examples of using Spacy for NER.
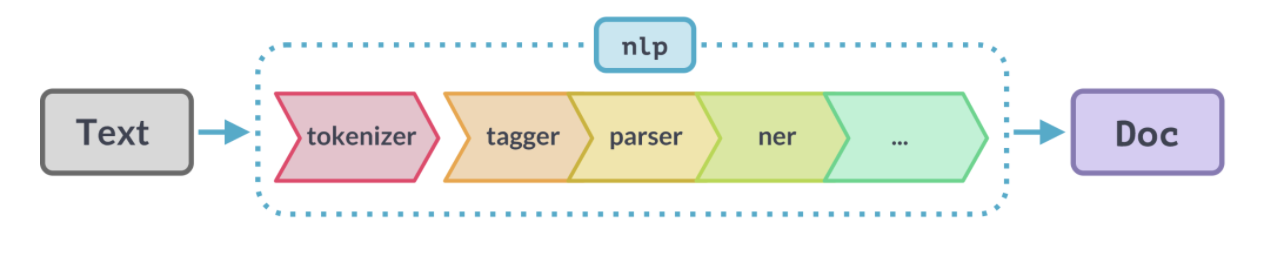
Make sure to install the latest version of python3, pip and spacy. Additionally, we'll have to download spacy core pre-trained models to use them in our programs directly.
Use Terminal or Command prompt and type in the following command after installing spacy:
python -m spacy download en_core_web_sm
Code:
# import spacy
import spacy
# load spacy model
nlp = spacy.load('en_core_web_sm')
# load data
sentence = "Apple is looking at buying U.K. startup for $1 billion"
doc = nlp(sentence)
# print entities
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)Output:
Apple 0 5 ORG
U.K. 27 31 GPE
$1 billion 44 54 MONEYWe’ve loaded a simple sentence here and applied NER with Spacy, and it works like magic. Let’s decode the program now.
Firstly, we’ve imported the spacy module into the program. Next, we load the spacy model into a variable named nlp. Next, we load the data into the model with the defined model and store it in a variable named doc. Now we iterate over the doc variable to find the entities and then print the word, its starting, ending characters, and the entity it belongs to.
This is a simple example: if we want to try this on real large datasets, we can use the medium and large models in spacy.
nlp = spacy.load('en_core_web_md')
nlp = spacy.load('en_core_web_lg')These work with high accuracy in identifying some common entities like names, location, organisation etc.
In the next section, let us look at some of the business applications where NER is of utmost need!
NER Business Example
Businesses generate a lot of data every day, especially documents like invoices, payslips, receipts etc. Owners and managers need to get a quick snapshot of key data. Using NET on documents will allow everyone on the team to search, edit, and analyse important transactions and details of all business processes.
Here are some of the characteristics of an ideal information extraction algorithm:
- Should be able to parse through all documents
- Read both electronic and non-electronically made documents
- Should be able to understand multiple languages and special characters
- Extract information from generic templates
- Identify fraudulent data
- Should be able to read data when scanned improperly
Building an algorithm with NER is not sufficient to address all the above challenges. This is where we'll have to bring in OCR and Deep Learning algorithms to do the pre-processing part and NER for final actions.

Now, let's look at how OCR and Deep Learning with NER can help build an ideal information extractor tool:
Step #1: OCR for Text Identification
OCR is a must-have tool for document extraction. This is because, with OCR, we can read and extract any text from various data formats. For example, OCR can identify text on PDFs, Images, Web Pages and many more. Hence, we need not worry if the documents are electronically generated or not. Say if we have tabular formats, OCR can save the coordination of the tables and then export them to deep learning programs to extract the line items with high accuracy. Also, building an OCR from scratch is less expensive; several open-source engines like Tesseract and train on custom data to build state-of-the-art OCR engines.
However, OCR's job is to find the text coordinates in a document and convert them into editable format irrespective of formatting and styles.
Step #2: Deep Learning for Information Extraction
However, OCR's job is to find the text coordinates in a document and convert them into editable format irrespective of formatting and styles.
Hence, using OCR isn't enough to extract specific regions of invoices or tables; we need a more intelligent algorithm that understands the invoice's structure and layout to identify specific regions of interest. For example, say we have invoices of different templates and want to extract all the tables, invoice-ids, invoice total and ignore the rest. The algorithm should exactly find the regions (coordinates) of these particular fields; to achieve this; deep learning models must be trained and fined tuned a lot. Below are some of the algorithms that are most familiar for this task:
- Invoice NET (Paper, Source Code)
- LayoutLM (Paper, Source Code)
- CUTIE (Paper, Source Code)
Step #3: NER on Text
With OCR and Deep Learning, we can extract regions from invoices. To make this more accurate, we'll be using NER. Consider the following example; for an unseen document; the deep learning model might not be accurate in identifying the bounding boxes for particular fields; NER can be handy in such cases. Below are some of the research papers:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Paper, Source Code)
- FLERT: Document-Level Features for Named Entity Recognition (Paper, Source Code)
Nanonets has interesting use cases and unique customer success stories. Find out how Nanonets can power your business to be more productive.

Conclusion
In this blog, we've deep-dived into the fundamentals of Named Entity Recognition and Information Extraction for text extraction. Next, we've looked at different steps on implementing NER from scratch using the BERT model. Further, we used pre-trained models and techniques to use the Spacy and NLTK libraries to perform entity recognition on actual data. Lastly, we discussed a real use case on how NER can help automate information extraction on real documents such as Invoice, Receipts and many more using OCR and deep learning.
References
- How to Fine-Tune BERT for Named Entity Recognition
- Named-entity recognition
- spaCy 101: Everything you need to know · spaCy Usage Documentation
Update July 2021: This post was originally published in June 2020 and has since been updated with new info based on latest advances/breakthroughs.
Here's a slide summarizing the findings in this article. Here's an alternate version of this post.



