













































How to easily extract data from pay slips using deep learning
How to OCR pay slips? This blog is a comprehensive overview of different methods of extracting structured text using OCR from salary pay slips to automate manual data entry.
Pay slips or Pay stubs, as they are more commonly known, are a common form of income verification used by lenders to check your credit-worthiness. If you're a working employee or have been in the past, no doubt you've encountered one. Usually, these payslips contain details such as an employee's earnings for a particular time, including other fields like their tax deductions, insurance amounts, social security numbers etc. These can be either paper or digital and sometimes sent via email or post.
Currently, lenders get scanned or digital PDFs of these payslips and manually enter details from them into their systems to issue a loan. This process is time-consuming, especially during peak seasons, leading to a long time from loan application to funds being released. What if you could scrape PDF versions of these payslips and reduce this time to a few seconds for faster loan processing to delight your customer?
In this blog, we'll be reviewing different ways one can automate information extraction of payslips (Payslip OCR or Payslip PDF extract) and save them as structured data using Optical Character Recognition (OCR). Further, we'll discuss the frequent challenges we encounter in building an accurate OCR integrated with Machine learning and deep learning models. Below is the table of contents.
How to extract text from Payslips with OCR?
In this section, we'll be discussing how we can make use of OCR based algorithms to extract information from payslips. If you're not aware of OCR, think of it as a computer algorithm that can read images of typed or handwritten text into text format. Out there, there are different - free and open-source tools on GitHub like Tesseract, Ocropus, Kraken, but have certain limitations. For example, Tesseract is very accurate in extracting organised text, but it does not perform well on unstructured data. Similarly, the other OCR tools have several limitations based on the fonts, language, alignment, templates etc. Now, coming back to our problem of extracting information from Payslips, an ideal OCR should be able to pull all the essential fields, irrespective of the above-discussed drawbacks. Now, before setting up an OCR, let's see the standard fields that we need to extract from a Payslip document.
- Net salary
- Gross salary
- Bank account
- Employer name
- Employer address
- Employee name
- Employee number
- Employee address
- Salary period
- Date of birth
- Days worked
- Hours worked
- In / out service date
- Hourly rate
- Tax rate
- Date of issue
Before we set up an OCR and look into outputs, we must realise that OCR doesn't know what kind of documents we're giving them to extract, they blindly identify the text and return them irrespective of fields or identifiers mentioned above. Now, we'll use Tesseract, which is a free and open-source OCR engine by Google. To learn more about configuring this on your system, and developing python scripts for scanned images, check out our guide on Tesseract here.
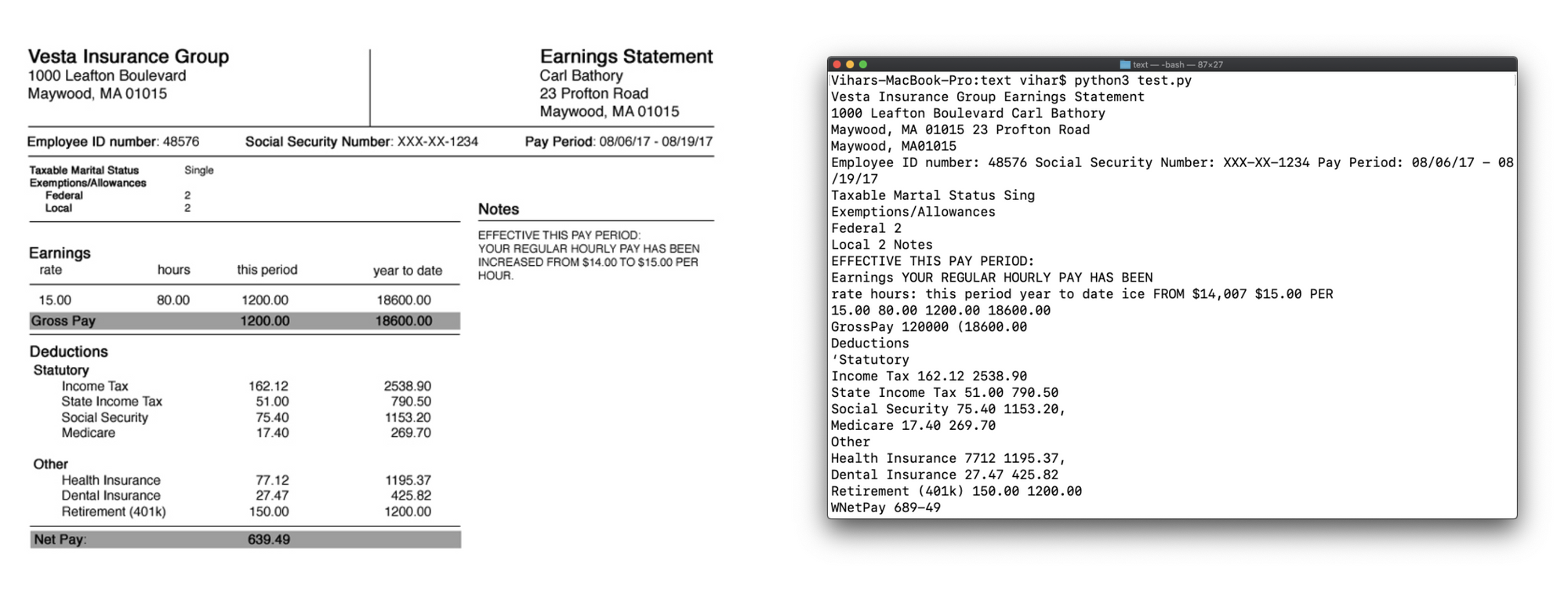
As we can clearly see, Tesseract identified all the text in the given image, irrespective of tables, positions and alignment of text and printed it out accurately. But it takes a lot of postprocessing to pick all the important fields and put them in a structured way. For example, say you only need to extract the tax deducted for an employee, Tesseract alone cannot do it. This is where machine learning and deep learning models come into the picture to intelligently identify the location of the fields and extract necessary values. We call this as key-value pair extraction, let’s discuss how we can achieve this in the next sections.

Drawbacks and Challenges
While scanning pay slips, we encounter different issues like capturing in wrong angles or dim lighting conditions. Also, after they are captured, it's equally important to check if they are original or faked. In this section, we'll discuss these critical challenges and how they can be addressed.
Improper Scanning
It's the most common problem while performing OCR. For high-quality scanned and aligned images, the OCR has a high accuracy of producing entirely searchable editable text. However, when a scan is distorted or when the text is blurred, OCR tools might have difficulty reading it, occasionally making inaccurate results. To overcome this, we must be familiar with techniques like image transforms and de-skewing, which help us align the image in a proper position.
Fraud & Blurry Image Checks
It’s important for companies and employees to check if pay slips are authentic or not. These are some of the traits which can help us check if the image is fake or not.
- Identify backgrounds for bent or distorted parts.
- Beware of low-quality images.
- Check for blurred or edited texts.
One algorithm that's familiar to overcome this task is the "Variance of Laplacian." It helps us find and examine the distribution of low and high frequencies in the given image.
Key-Value pair Data Extraction for Pay slips
As discussed above, key-value extraction will search for user-defined keys that are static text on forms and then identify the associated values to them. To achieve this technique first, one must be familiar with Deep Learning. We'll also have to make sure that these deep learning algorithms are applicable for different templates, as in the same algorithm should be appropriate for documents of other formats. After the algorithm finds the position of required keys and values, we then use OCR to extract the text from it.
Here is an example of how tesseract extracts text,
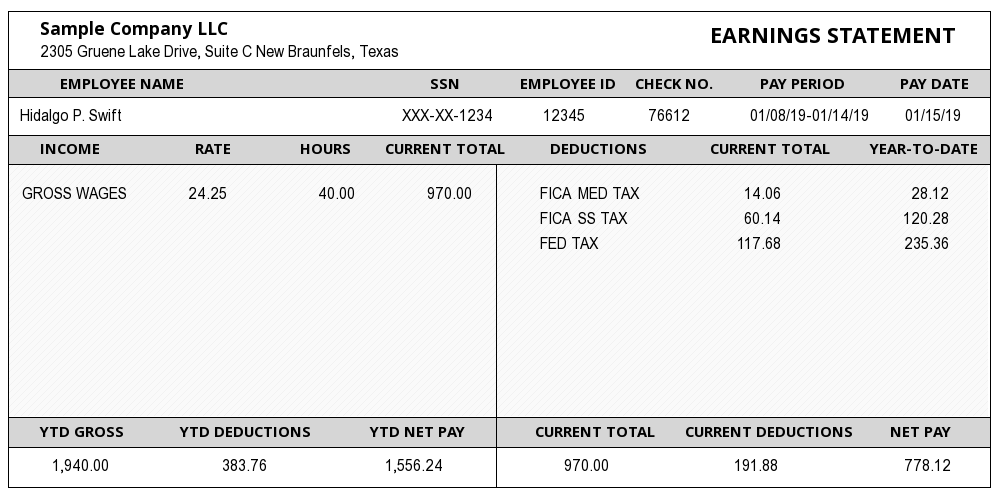
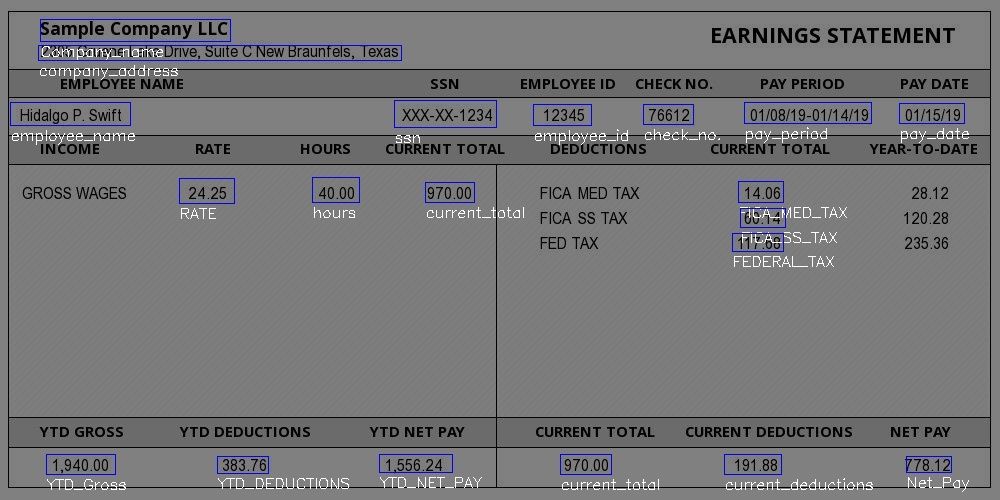
Sample Company LLC EARNINGS STATEMENT
2305 Gruene Lake Drive, Suite C New Braunfels, Texas
Hidalgo P. Swift XXX-XX-1234 12345 76612 01/08/19-01/14/19 0115/19
GROSS WAGES 24.25 40.00 970.00 FICA MED TAX 14.06 28.12
FICA SS TAX 60.14 120.28
FED TAX 117.68 235.36
1,940.00 383.76 1,556.24 970.00 191.88 778.12
While for key value pair extraction we'll have a a JSON output of the required keys and values of the given pay slip. The output JSON data can be saved as structured data into excel sheets, databases and CRM systems by using simple automation scripts. In the next section, we'll discuss a few deep learning techniques for key-value pair extraction on documents like Pay slips.
Deep Learning Models for Pay slip IE
There are two ways for information extraction using deep learning, one building algorithms that can learn from images, and the other from the text.
Alright, now let's dive into some deep learning and understand how these algorithms identify key-value pairs from images or text. Also especially for pay slips, it's essential to extract the data in the tables, as most of the earnings and deductions in a pay slip are mentioned in tabular format. Now, let's review a few popular deep learning architectures for scanned documents.
In the research, CUTIE (Learning to Understand Documents with Convolutional Universal Text Information Extractor), Xiaohui Zhao proposed extracting key information from documents, such as receipts or invoices, and preserving the interesting texts to structured data. The heart of this research is the convolutional neural networks, which are applied to texts. Here, the texts are embedded as features with semantic connotations. This model is trained on 4, 484 labelled receipts and has achieved 90.8%, 77.7% average precision on taxi receipts and entertainment receipts, respectively.
BERTgrid is a popular deep learning-based language model for understanding generic documents and performing key-value pair extraction tasks. This model also utilizes convolutional neural networks based on semantic instance segmentation for running the inference. Overall the mean accuracy on selected document header and line items was 65.48%.
In DeepDeSRT, Schreiber et al. presented the end to end system for table understanding in document images. The system contains two subsequent models for table detection and structured data extraction in the recognized tables. It outperformed state-of-the-art methods for table detection and structure recognition by achieving F1-measures of 96.77% and 91.44% for table detection and structure recognition, respectively. Models like these can be used to extract values from tables of pay slips exclusively.
Want to find out more about how Nanonets can transform your payroll processes?
Further Reading


