













































Extracting Invoice Tables

Introduction
Invoice and receipts have been in existence for centuries in the commercial world as printed records explaining our cash flows. From individuals keeping track of their daily spending to corporations keeping track of their annual budgets, keeping good records of invoices is the backbone to anybody’s financial success.
Invoices are usually presented in table formats, although how exactly the tables are formatted may vary from company to company. The variations are never problems to human understanding, yet they became a great challenge during the recent shift of digitalising finance records, when companies attempted to automate the process of extracting invoice tables. With the different formats, a hard-coded scanning method can never be fully accurate -- one must incorporate methods in image processing, computer vision, and language understanding in order to perform proper extraction.
This article introduces the importance of invoice table extraction particularly for businesses and accounting, then dives into the deeper concepts around image classification, object detection, and OCR for the full extraction pipeline, and finally provides coding and Nanonets tutorials as well as service comparisons from multiple solutions.
Looking to extract tables from Invoices? Try Nanonets' AI-based OCR tool to extract tabular data from Invoices and convert them to Excel or Spreadsheet formats.
The Importance of Invoice Table Extraction
The task of invoice table extraction, while seemingly easy, becomes perplexing when it requires high accuracy and precision without human supervision. The following section describes how— for ordinary businesses and accounting firms — accurate invoice table extractions plays an important role.

Businesses
Cash flow is crucial for any business irrespective of the size, business model, or target consumers. When the company source of buying and selling are from a single source, it is easy to keep track through quick manual comparisons of receipts — this is often not the case especially for large businesses. Money can flow in and out of the company from various sources, often with different formats of receipts and invoices. The challenge becomes even bigger when payments are international with different languages. Every year, companies spend tremendous amounts of resources to hire labourers for a task that seems to be easy and yet is error prone. Therefore, an automated method to scan and extract invoice tables would ultimately be more than helpful in saving cost, time, & resources for these companies.
Accounting Firms

The same problem deteriorates further when it comes to accounting firms. The types of receipts can vary dramatically due to the number of clients, not to mention the problems when the invoices of different fields vary drastically in terms of fonts (some may even be handwritten). In addition, a lot of information required for any payment reconciliation or tax reporting are only applicable to accounting firms, and therefore extracting invoice tables becomes an even more crucial process.
The size of the accounting firm also matters. While the Big Four may be able to hire thousands for labour-intensive work, small accounting firms can benefit dramatically due to the cost savings with automatic table extraction from invoices.
Looking to extract tables from Invoices? Try Nanonets' AI-based OCR tool to extract tabular data from Invoices and convert them to Excel or Spreadsheet formats.
How?

The question of “how” is what daunts all the firms. The seemingly easy, almost trivial problem of extracting a table becomes so hard when no human surveillance is available for double checking/verification. This section decomposes the problem of extraction into the more fundamental concepts and introduces in a bottom-up manner how to tackle the extraction of tables in invoices.
Convolutional Neural Networks (CNNs)
We must first understand what is going on with CNNs before understanding how we can utilize them for our task.
A convolutional network is part of the neural network family blooming in the deep learning era. Essentially, CNNs are done through kernels, or windows that slide through an entire image. As you slide the kernel across the image, you multiply the weights of the kernel with the overlaying part of the image which ultimately leads to features extracted from the image. Through a loss function and backpropagation just like all other neural networks, we can learn the weights that extract the best features to determine what is going on inside the image.
This concept can be applied to multiple tasks, from image classification, object detection, to instance segmentation, all of them are built on backbones revolving around the idea of convolutions. We will briefly talk about the tasks we will need for invoice extraction involving CNNs.
Image Classification
Image classification is one of the core problems in the computer vision domain. The goal is to determine on a high level what is the main thing inside the image. The task is rather simple with the help of CNNs, as we can use a simple binary cross entropy loss (yes or no) on telling the network whether it is correct or not during training, which will usually lead to fairly good results.
Object Detection
This task is a little more difficult than the classification task. Not only do we have to determine the object within the image, but also draw a bounding box to locate where in the image the object exists. On top of a binary cross entropy loss, we also have to impose additional tools such as bounding box regression and multi-scaling to achieve high accuracies in this task
Recurrent Neural Network (RNNs)
On the other hand, another network that would come into use is RNNs. In contrast to CNNs that deal with visual data, RNN focuses on dealing with time-series data, where data at other timeframes may affect the results at these frames. RNN propagates this information so that previous data is also factored into the current prediction. It can also work bidirectionally if the data from both directions is available.
Natural Language Processing
The most predominant area of RNN applications fall within the concept of natural language process. Language itself is something that relies on previous data (e.x., what the next word is going to be is almost purely dependent on what words have come out in the phrase), and hence the results for all language tasks have been improved with variants of recurrent networks.
Everything Together
Now that we have all the building blocks together, here is how everything is combined for extracting invoice tables:
- Classifying the Type of Invoices: With so many different types of invoices, one may first need a network that classifies invoice within each image to determine the type of invoice first. Different invoices may have different models for table detection moving further.
- Table and Cell Detection: We can then treat the idea of invoice table detection as an object detection task to determine where the table is within the image. We can also detect where each table cell is with the same method.
- Language Understanding: We can adopt recurrent networks to determine the words/figures within the cell and thus perform proper extraction into designated, computer-understandable formats (e.g., CSV or JSON files)
Looking to extract tables from Invoices? Try Nanonets' AI-based OCR tool to extract tabular data from Invoices and convert them to Excel or Spreadsheet formats.
Using Google Vision API
Google Vision API is one of the powerful tools that can perform table extraction regardless of input types (e.g., invoices).
Google Vision API is fairly straightforward to setup. One may refer to its official guidance on https://cloud.google.com/vision/docs/quickstart-client-libraries for the detailed setup procedure.
We can simply perform Table Parsing with the following:
from google.cloud import documentai_v1beta2 as documentai
def parse_table(
project_id="YOUR_PROJECT_ID",
input_uri="gs://cloud-samples-data/documentai/invoice.pdf",
):
"""Parse a form"""
client = documentai.DocumentUnderstandingServiceClient()
gcs_source = documentai.types.GcsSource(uri=input_uri)
# mime_type can be application/pdf, image/tiff,
# and image/gif, or application/json
input_config = documentai.types.InputConfig(
gcs_source=gcs_source, mime_type="application/pdf"
)
# Improve table parsing results by providing bounding boxes
# specifying where the box appears in the document (optional)
table_bound_hints = [
documentai.types.TableBoundHint(
page_number=1,
bounding_box=documentai.types.BoundingPoly(
# Define a polygon around tables to detect
# Each vertice coordinate must be a number between 0 and 1
normalized_vertices=[
# Top left
documentai.types.geometry.NormalizedVertex(x=0, y=0),
# Top right
documentai.types.geometry.NormalizedVertex(x=1, y=0),
# Bottom right
documentai.types.geometry.NormalizedVertex(x=1, y=1),
# Bottom left
documentai.types.geometry.NormalizedVertex(x=0, y=1),
]
),
)
]
# Setting enabled=True enables form extraction
table_extraction_params = documentai.types.TableExtractionParams(
enabled=True, table_bound_hints=table_bound_hints
)
# Location can be 'us' or 'eu'
parent = "projects/{}/locations/us".format(project_id)
request = documentai.types.ProcessDocumentRequest(
parent=parent,
input_config=input_config,
table_extraction_params=table_extraction_params,
)
document = client.process_document(request=request)
def _get_text(el):
"""Convert text offset indexes into text snippets."""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in el.text_anchor.text_segments:
start_index = segment.start_index
end_index = segment.end_index
response += document.text[start_index:end_index]
return response
for page in document.pages:
print("Page number: {}".format(page.page_number))
for table_num, table in enumerate(page.tables):
print("Table {}: ".format(table_num))
for row_num, row in enumerate(table.header_rows):
cells = "\t".join([_get_text(cell.layout) for cell in row.cells])
print("Header Row {}: {}".format(row_num, cells))
for row_num, row in enumerate(table.body_rows):
cells = "\t".join([_get_text(cell.layout) for cell in row.cells])
print("Row {}: {}".format(row_num, cells))
Note that this is for online PDFs of fairly small size. You may refer to the following for large file offline processing:
import re
from google.cloud import documentai_v1beta2 as documentai
from google.cloud import storage
def batch_parse_table(
project_id="YOUR_PROJECT_ID",
input_uri="gs://cloud-samples-data/documentai/form.pdf",
destination_uri="gs://your-bucket-id/path/to/save/results/",
timeout=90,
):
"""Parse a form"""
client = documentai.DocumentUnderstandingServiceClient()
gcs_source = documentai.types.GcsSource(uri=input_uri)
# mime_type can be application/pdf, image/tiff,
# and image/gif, or application/json
input_config = documentai.types.InputConfig(
gcs_source=gcs_source, mime_type="application/pdf"
)
# where to write results
output_config = documentai.types.OutputConfig(
gcs_destination=documentai.types.GcsDestination(uri=destination_uri),
pages_per_shard=1, # Map one doc page to one output page
)
# Improve table parsing results by providing bounding boxes
# specifying where the box appears in the document (optional)
table_bound_hints = [
documentai.types.TableBoundHint(
page_number=1,
bounding_box=documentai.types.BoundingPoly(
# Define a polygon around tables to detect
# Each vertice coordinate must be a number between 0 and 1
normalized_vertices=[
# Top left
documentai.types.geometry.NormalizedVertex(x=0, y=0),
# Top right
documentai.types.geometry.NormalizedVertex(x=1, y=0),
# Bottom right
documentai.types.geometry.NormalizedVertex(x=1, y=1),
# Bottom left
documentai.types.geometry.NormalizedVertex(x=0, y=1),
]
),
)
]
# Setting enabled=True enables form extraction
table_extraction_params = documentai.types.TableExtractionParams(
enabled=True, table_bound_hints=table_bound_hints
)
# Location can be 'us' or 'eu'
parent = "projects/{}/locations/us".format(project_id)
request = documentai.types.ProcessDocumentRequest(
input_config=input_config,
output_config=output_config,
table_extraction_params=table_extraction_params,
)
requests = []
requests.append(request)
batch_request = documentai.types.BatchProcessDocumentsRequest(
parent=parent, requests=requests
)
operation = client.batch_process_documents(batch_request)
# Wait for the operation to finish
operation.result(timeout)
# Results are written to GCS. Use a regex to find
# output files
match = re.match(r"gs://([^/]+)/(.+)", destination_uri)
output_bucket = match.group(1)
prefix = match.group(2)
storage_client = storage.client.Client()
bucket = storage_client.get_bucket(output_bucket)
blob_list = list(bucket.list_blobs(prefix=prefix))
print("Output files:")
for blob in blob_list:
print(blob.name)
Details for implementation can be found here: https://cloud.google.com/document-ai/docs/process-tables.
Converting to Images
Invoice tables are usually presented as scans in PDF/image formats. While for images it is fairly straightforward to directly jump into computer vision techniques, PDFs requires an extra step of image conversion.
To convert PDFs to images, one may use the pdf2image library by installing the following:
pip install pdf2imageThen convert with:
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
images = convert_from_path('example.pdf')
images = convert_from_bytes(open('example.pdf','rb').read())The example.pdf can even be more than one page, and all the pages would be converted to multiple images for usage.
For more information on the code, you can refer to the official documentation in https://pypi.org/project/pdf2image/
You may then use libraries such as opencv-python to try detect tables using image processing techniques.
Looking to extract tables from Invoices? Try Nanonets' AI-based OCR tool to extract tabular data from PDFs and convert them to Excel or Spreadsheet formats.
Nanonets, Making Everything Just So Simple
While the above tutorial is straightforward for people with computer science backgrounds, it is not the most straightforward way for businesses in other fields. Luckily, Nanonets offers one of the best table extraction technologies particularly for invoices. Here is a short tutorial of how to use it:
Step 1.
Go to nanonets.com and register/log in.
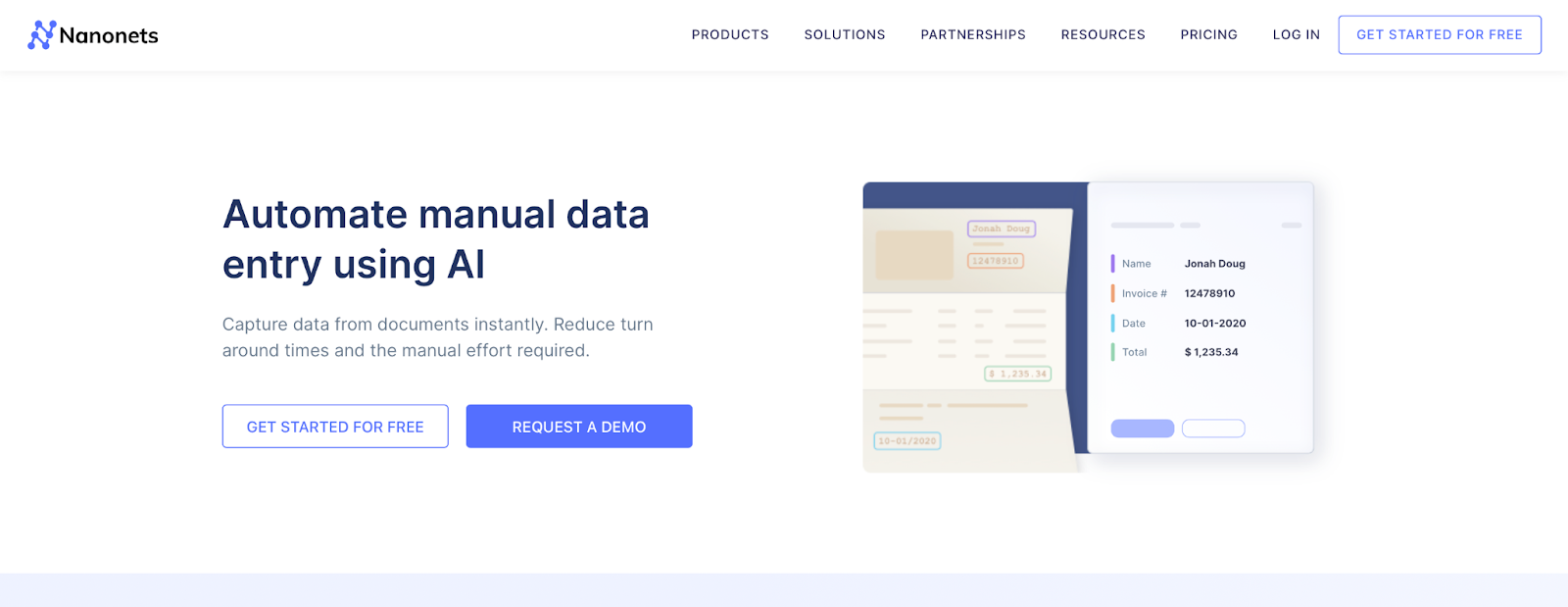
Step 2.
After registration, go to the “Choose to get started” area, where all the pre-built extractors are made and click on the “Tables” tab for the extractor designed for extracting tabular data.
Step 3.
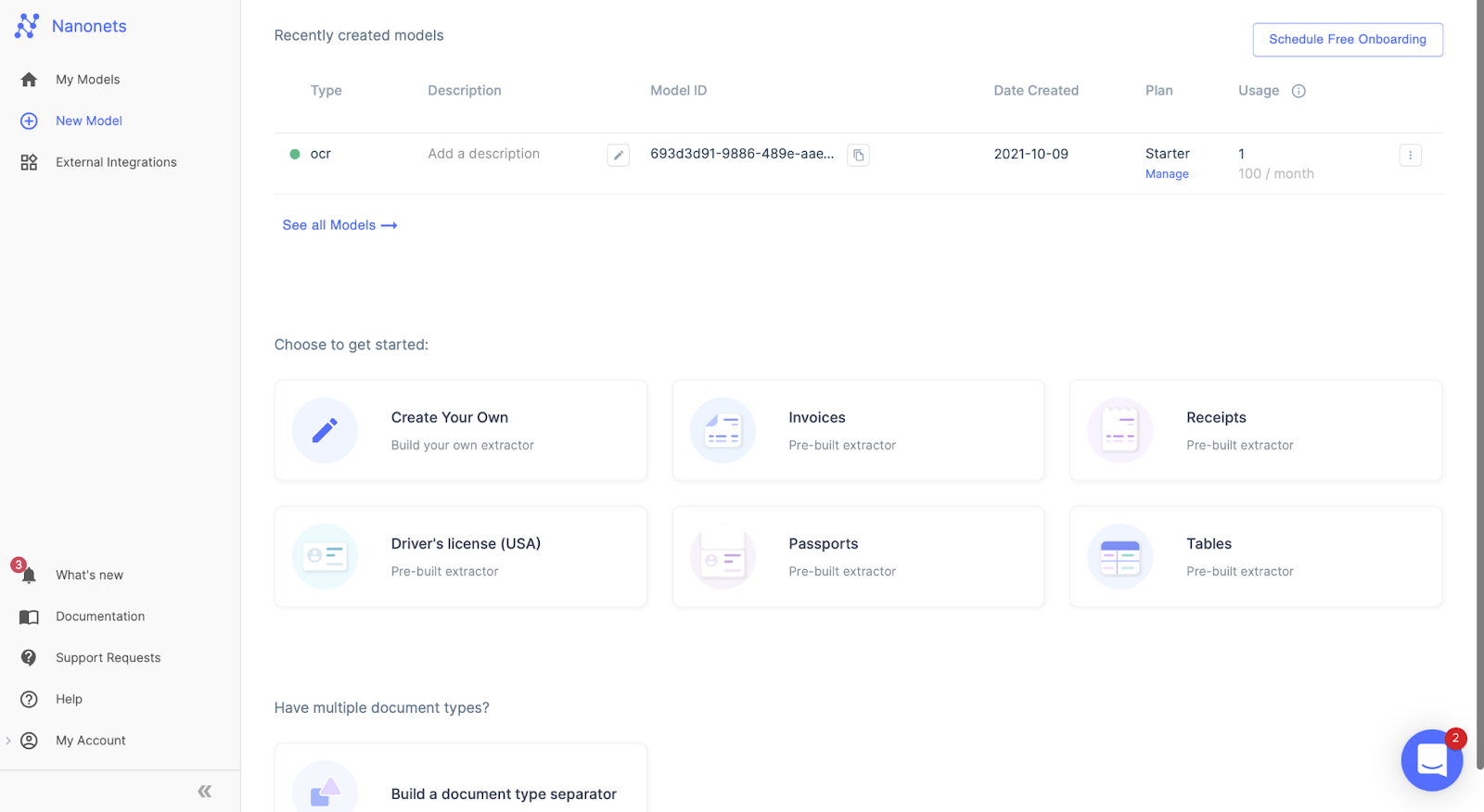
After a few seconds, the extract data page will pop up saying it is ready. Upload the file for extraction.

Step 4.
After processing, Nanonets extracts all tabular information accurately, even skipping the empty spaces! The data can also be converted into JSON for download and further computations.

Conclusion
This article covers the concepts behind invoice table extraction, with details on the state-of-the-art technology and two tutorials. Hopefully you can get your business going and start automating table extraction from invoices!


