













































How to extract data from image in 2024?


Introduction
Extracting data from an image can be a cumbersome process. Most people manually key in the data from the image; but this is both time-consuming and inefficient when you have a lot of images to deal with.
Image to data converters offer a neat way to extract text or data from images.
While such tools do a good job, the extracted data is often presented in an unstructured manner that results in a lot of post processing.
An AI-driven OCR like Nanonets can pull data from images and present it in a neat, organized & structured manner.
Nanonets extracts data from images accurately, at scale, and in multiple languages. Nanonets is the only text recognition OCR that presents extracted data in neatly structured formats that are entirely customizable. Captured data can be presented as tables, line items, or any other format.
Here are three advanced methods in which you can use Nanonets OCR to detect and extract data from images and other document types:
Extract data from image using Nanonets' zero training AI
Just specify the fields you want to extract and Nanonets can intuitively capture the relevant data. No training or sample documents required.
Zero shot extraction allows you to use natural language to describe the data you want to extract from a document.
Extract data from image using Nanonets' zero training AI
Step 1: Define your fields
Identify and Specify the fields you want to extract from your document
Step 2: Upload your images or documents
Simply upload the image/document you want to extract data from.
Step 3: Start extracting
Download / export the extracted structured data once ready. Or integrate the data with your business tools.
Does your business deal with text recognition in digital documents, images or PDFs? Have you wondered how to extract text from images accurately?
Extract data from image using Nanonets' pre trained OCR models
Nanonets has pre-trained OCR models for the specific image types listed below. Each pre-trained OCR model is trained to accurately relate data or text in the image type to an appropriate field like name, address, date, expiry etc. and present the extracted data in a neat and organized manner.
- Invoices
- Receipts
- Purchase orders
- Bank statements
- Bills of Lading
- Driver’s license (US)
- Passports
- and more...
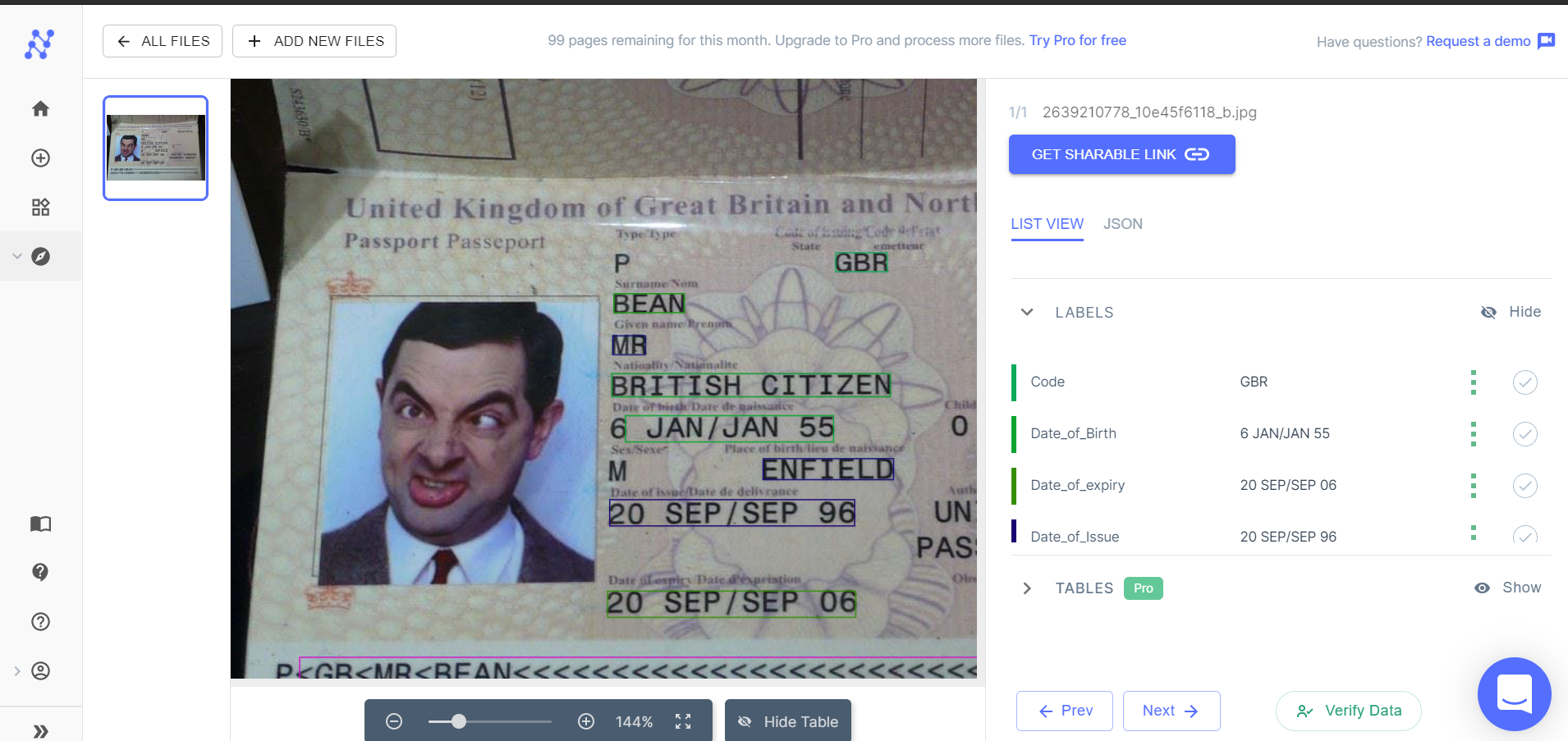
Here's a quick demo of the pre-trained receipt OCR model:
Nanonets extracting data from images of receipts
Step 1: Select an appropriate OCR model
Login to Nanonets and select an OCR model that is appropriate to the image from which you want to extract text and data. If none of the pre-trained OCR models suit your requirements, you can skip ahead to find out how to create a custom OCR model.
Step 2: Add files
Add the files/images from which you want to extract text. You can add as many images as you like.
Step 3: Test
Allow a few seconds for the model to run and extract text from the image.
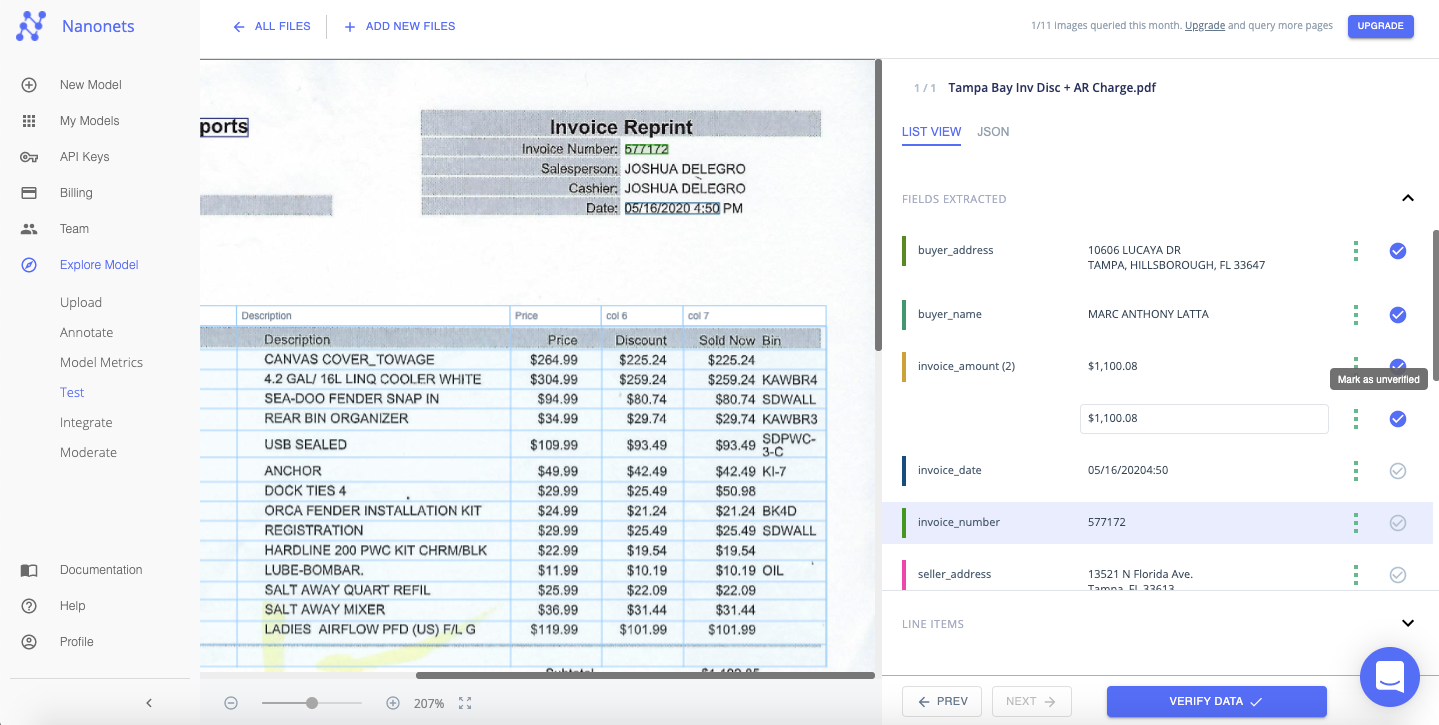
Step 4: Verify
Quickly verify the data extracted from each file, by checking the table view on the right. You can easily double-check whether the text has been correctly recognized and matched with an appropriate field or tag.
You can even choose to edit/correct the field values and labels at this stage. Nanonets is not bound by the template of the image.
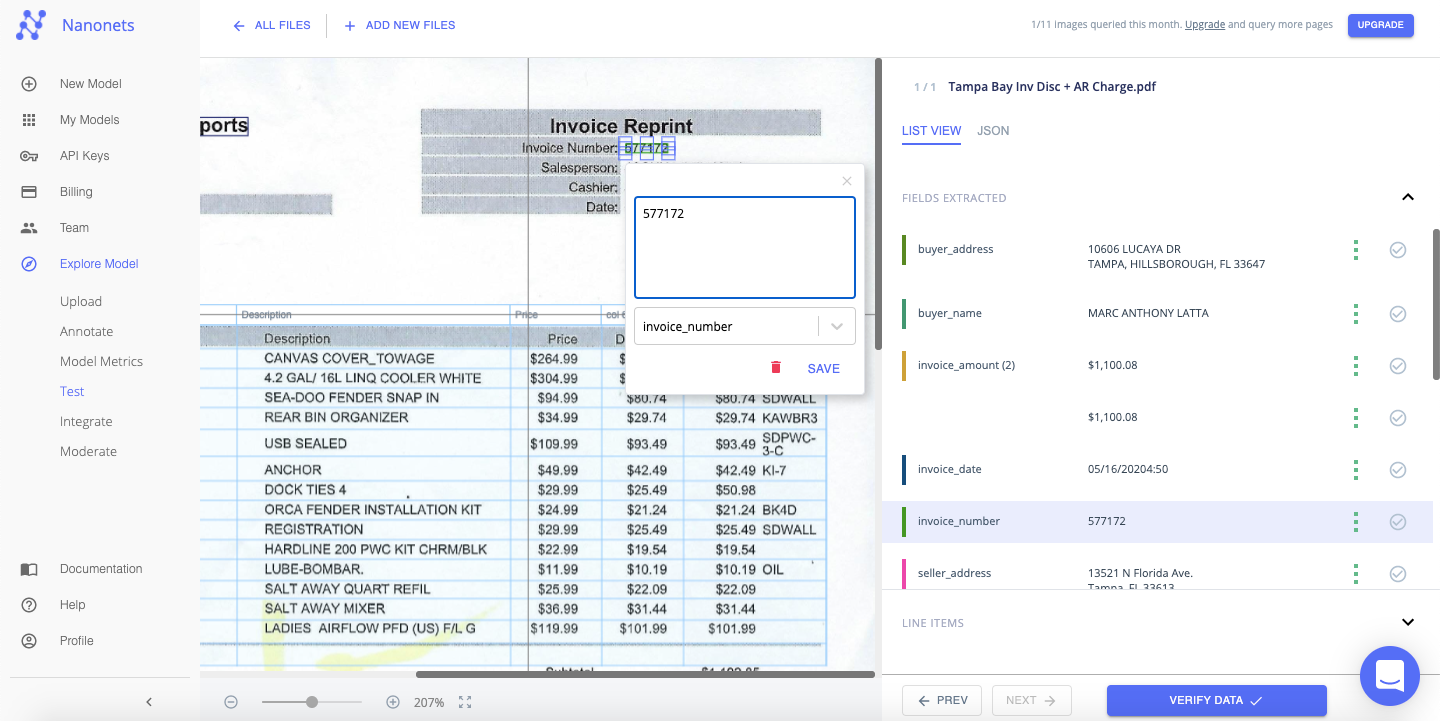
The extracted data can be displayed in a “List View” or “JSON” format.
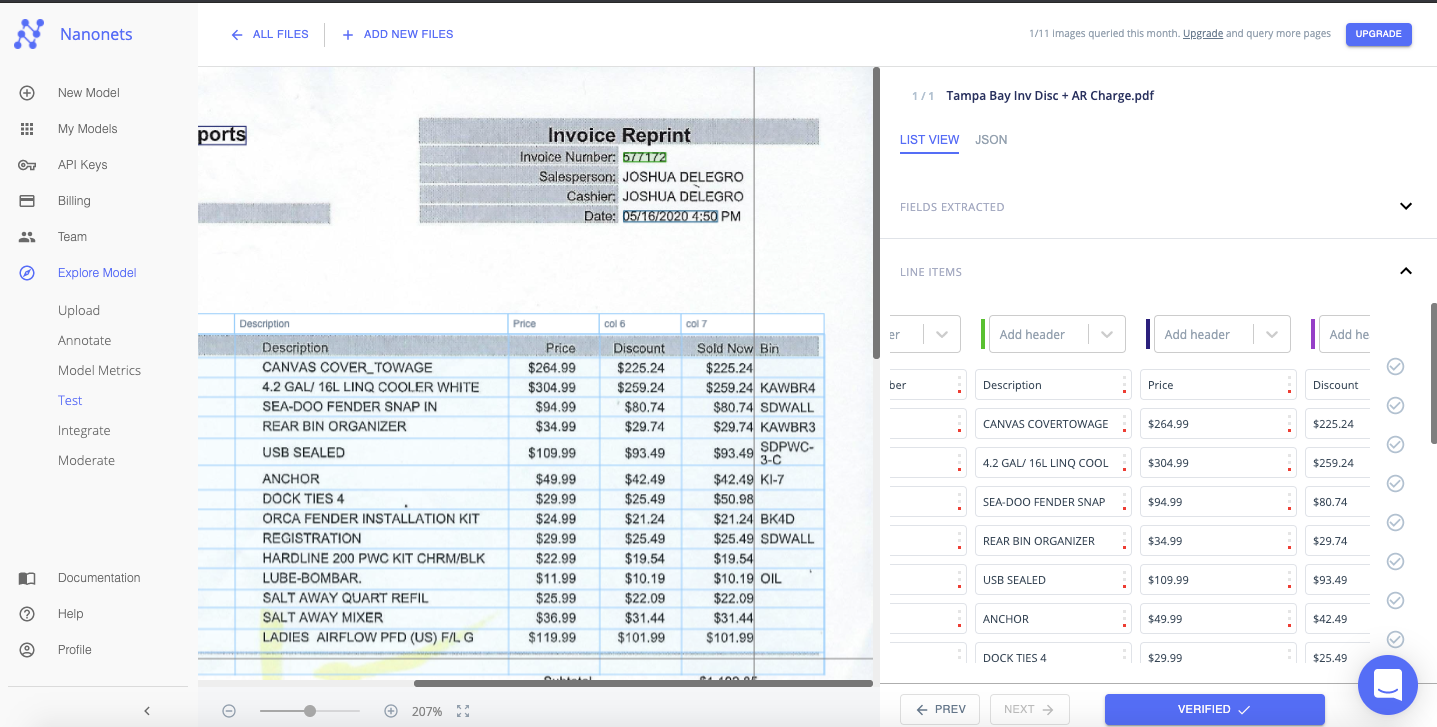
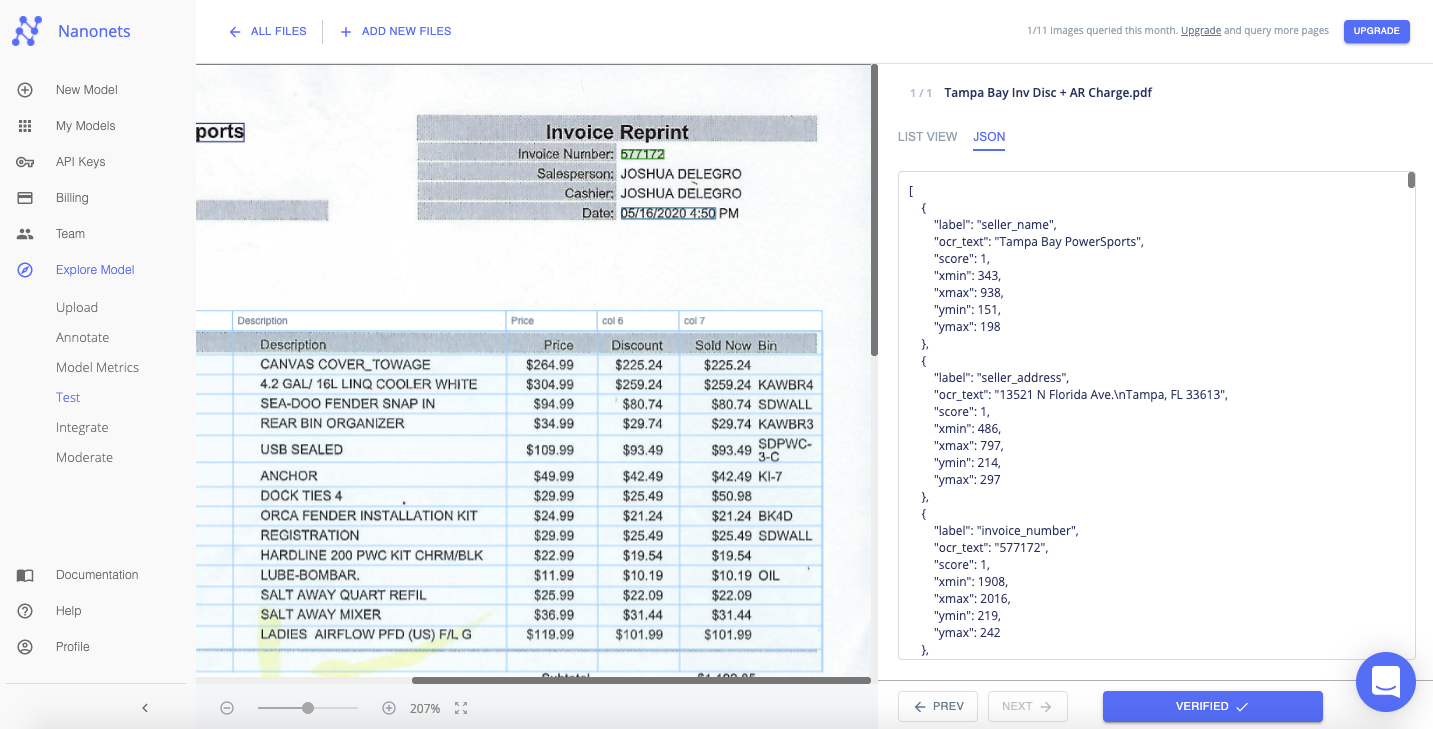
The extracted text displayed as a list or JSON output
You can tick the checkbox beside each value or field you verify or click “Verify Data” to proceed instantly.
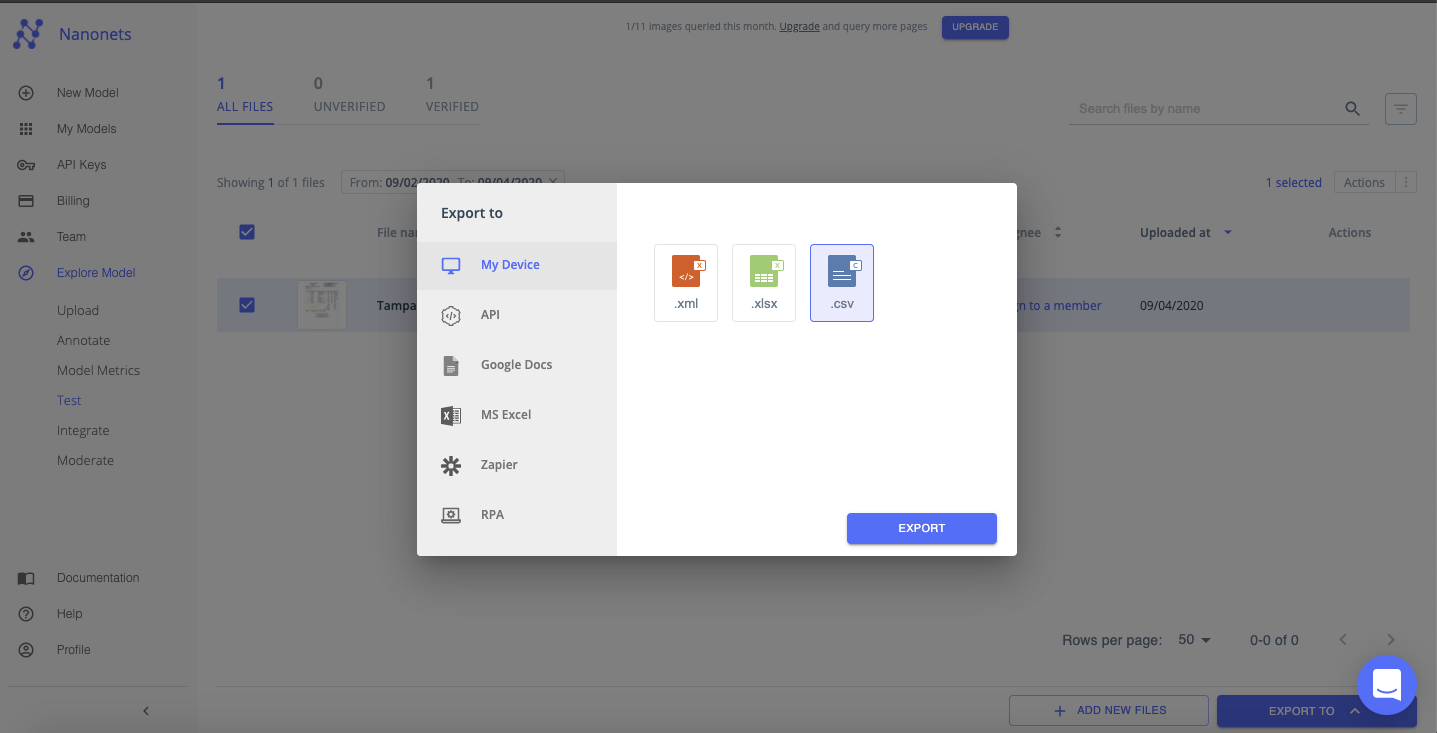
Step 5: Export
Once all the files have been verified. You can export the neatly organized data as an xml, xlsx or csv file.
Train your own OCR models with NanoNets API
Here’s a detailed guide to train your own OCR models using the Nanonets API. In the documentation, you will find ready to fire code samples in Python, Shell, Ruby, Golang, Java, and C#, as well as detailed API specs for different endpoints.
Here's a step-by-step guide to training your own model using the Nanonets API:
Step 1: Clone the Repo
git clone https://github.com/NanoNets/nanonets-ocr-sample-python
cd nanonets-ocr-sample-python
sudo pip install requests
sudo pip install tqdm
Step 2: Get your free API Key
Get your free API Key from https://app.nanonets.com/#/keys
Step 3: Set the API key as an Environment Variable
export NANONETSAPIKEY=YOURAPIKEYGOESHERE
Step 4: Create a New Model
python ./code/create-model.py
Note: This generates a MODEL_ID that you need for the next step
Step 5: Add Model Id as Environment Variable
export NANONETSMODELID=YOURMODELID
Step 6: Upload the Training Data
Collect the images of object you want to detect. Once you have dataset ready in folder images (image files), start uploading the dataset.
python ./code/upload-training.py
Step 7: Train Model
Once the Images have been uploaded, begin training the Model
python ./code/train-model.py
Step 8: Get Model State
The model takes ~30 minutes to train. You will get an email once the model is trained. In the meanwhile you check the state of the model
watch -n 100 python ./code/model-state.py
Step 9: Make Prediction
Once the model is trained. You can make predictions using the model
python ./code/prediction.py PATHTOYOURIMAGE.jpg
Why Nanonets is the best OCR for data extraction from images
The benefits of using Nanonets over other OCR APIs go beyond just better accuracy with respect to extracting data from images.
Here are 7 reasons why you should consider using the Nanonets OCR for data recognition instead:
1. Working with custom data
Most OCR software are quite rigid on the type of data they can work with. Training an OCR model for a use case requires a large degree of flexibility with respect to its requirements and specifications; an OCR for invoice processing will vastly differ from an OCR for passports! Nanonets isn’t bound by such rigid limitations. Nanonets uses your own data to train OCR models that are best suited to meet the particular needs of your business.
2. Working with non-English or multiple languages
Since Nanonets focuses on training with custom data, it is uniquely placed to build a single OCR model that could extract text from images in any language or multiple languages at the same time.
3. Requires no post-processing
Data extracted using OCR models needs to be intelligently structured and presented in an intelligible format; otherwise considerable time and resources go into re-organizing the data into meaningful information. While most OCR tools simply grab and dump data from images, Nanonets extracts only the relevant data and automatically sorts them into intelligently structured fields making it easier to view and understand.
4. Learns continuously
Businesses often face dynamically changing requirements and needs. To overcome potential roadblocks, Nanonets allows you to easily re-train your models with new data. This allows your OCR model to adapt to unforeseen changes.
5. Handles common data constraints with ease
Nanonets leverages AI, ML & Deep Learning techniques to overcome common data constraints that greatly affect text recognition & extraction. Nanonets OCR can recognize and handle handwritten text, images of text in multiple languages at once, images with low resolution, images with new or cursive fonts and varying sizes, images with shadowy text, tilted text, random unstructured text, image noise, blurred images and more. Traditional OCR APIs are just not equipped to perform under such constraints; they require data at a very high level of fidelity which isn’t the norm in real life scenarios.
6. Requires no in-house team of developers
No need to worry about hiring developers and acquiring talent to personalize Nanonets API for your business requirements. Nanonets was built for hassle-free integration. You can also easily integrate Nanonets with most CRM, ERP or RPA software.
7. Customize, customize, customize
You can capture as many fields of text/data that you like with Nanonets OCR. You can even build custom validation rules that work for your specific text recognition and data extraction requirements. Nanonets is not bound by the template of your document at all. You can capture data in tables or line items or any other format!


