













































Document OCR - The best way to process documents automatically
Not only does OCR software eliminate the need for manual data entry, which can be both time-consuming and more prone to errors, but it can also help businesses easily search through large amounts of documents for specific information. This way, they can quickly find what they need without going through each document manually, making record-keeping less of a burden and more streamlined. In addition, by employing OCR software, businesses can easily stay organized and updated.
With the following data, we can understand why OCR software is necessary to convert and store data.
- According to AIIM's 2019 study, around 71% of organizations still deal with paper daily.
- An average office employee uses 10,000 sheets of paper every year.
- The global document management systems market size is expected to grow from USD 5.55 billion in 2022 to USD 16.42 billion by 2029 at a Compound Annual Growth Rate (CAGR) of 19.6% during the forecast period.
- The cost of processing a paper invoice can range from $4 to $30, while the cost of processing an electronic invoice can range from $0.30 to $3.
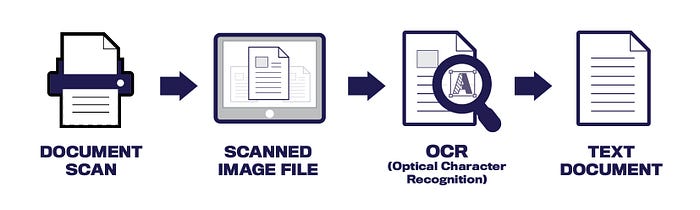
How does OCR Work?
This technology enables computers to recognize text from scanned documents, images, and PDFs using pattern recognition algorithms to identify characters in an image and convert them into machine-readable text.
It first identifies each character in the image, then compares it to a database of known characters to determine its identity.
Once identified, the characters can be converted into editable text for further processing or storage.
OCR technology has revolutionized document processing by converting physical documents into digital formats easier and faster.
Source: medium.com
Have an OCR use case in mind?
Nanonets OCR software is easy to use, setup and provides 95%+ OCR accuracy. Extract data from PDFs, images, emails, and more on autopilot.
What is Document OCR?
Document OCR (Optical Character Recognition) software is an incredibly helpful tool that has simplified extracting data from physical documents. By converting them to digital formats, businesses can easily access important information, saving time and increasing efficiency. With OCR software, repetitive tasks, like data entry, can be automated, freeing up valuable time and resources.
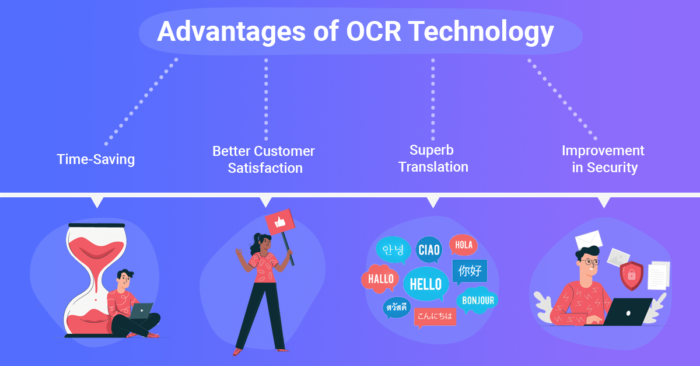
Advantages of Document OCR
No doubt, Document OCR has revolutionized document management and data entry processes. Here are some of the advantages of using OCR technology for document management.
Source: www.idenfy.com
Time and Cost Savings
OCR technology converts printed or handwritten documents into digital formats quickly and accurately. This process eliminates manual data entry, which can be time-consuming and costly. OCR software can process thousands of documents in minutes, thus saving time and resource costs.
Improved Accuracy
The OCR software reads and converts documents with exceptional accuracy, minimizing the common errors in manual data entry. The accuracy level of OCR software is usually around 99.8%, which is much higher than human performance.
This higher level of accuracy helps minimize document errors and inconsistencies, thus improving the overall quality and efficiency of operations.
Easy Search and Retrieval of Information
Once documents are converted into digital formats using OCR, they can be easily searched and retrieved using keywords or phrases. OCR software can also recognize and categorize various documents, making it easier for users to find specific information quickly.
Increased Productivity
Using OCR technology eliminates the need for manual data entry, which can free up employees’ time to focus on other important tasks. As a result, employees can spend more time on complex or value-added activities that require human judgment, expertise, and creativity. As a result, it ultimately leads to increased productivity and higher-quality work.
Better Security and Compliance
OCR technology can provide enhanced security and compliance measures by allowing access controls and automatically tracking document changes. The software can also monitor and alert users to unauthorized access or document changes. As a result, it helps ensure that documents are secure and compliance standards are maintained.
Have an OCR use case in mind?
Nanonets OCR software is easy to use, set up and provides 95%+ OCR accuracy. Extract data from PDFs, images, emails, and more on autopilot.
Common Applications of Document OCR
Data entry and extraction
For the data entry and extraction, we can take the example of the use of Document OCR in the hospital industry. Hundreds of thousands of data are stored in hospitals as physical papers or digital images daily.
With the use of Document OCR, this data can be readily scanned and converted into more accessible text-based files. Not only it saves data entry time by 90%, but it also improves accuracy.
Invoicing and billing automation
Document OCR has revolutionized how companies manage and operate their invoicing and billing. We can take the example of Nanonets document processing. It is an AI-based OCR software that can extract data from invoices or bills, purchase orders, or any other document.
Companies can use it to automate their invoicing and billing tasks, and the extracted data can be used to generate invoices much faster.
Contract management
For the utilization of Document OCR in contract management, we can take the example of an International Bank that needs to automate its contract processes.
When the contracts are stored in paper form, they take up too much space and are equally difficult to access and manage.
By using Document OCR, banks can scan and extract contact information and store them in a cloud-based system, so it is easily accessible as well.
Document OCR can also automate certain aspects of the contracts, as it can quickly notify when some clause on the contract is about to expire or is changed.
HR document management
A multinational company can utilize Document OCR to efficiently extract and store all employee information from physical documents to a cloud-based system. It can be easily accessed and utilized when needed.
Healthcare records management
OCR is also widely used in healthcare records management. For example, it allows healthcare providers to convert handwritten notes, lab reports, and other medical documents into digital formats, providing a more efficient and accurate medical record-keeping system.
Legal document processing
In legal document processing, OCR technology can save time and improve accuracy. Lawyers can extract data from legal documents and automate contract reviews, saving work hours.
Insurance document management
Insurance document management is also a natural fit for OCR. Insurance companies can automate the processing of claims and policies, eliminating the need for manual document sorting and data entry and minimizing errors.
ERP Automation
OCR can also support ERP automation. For example, extracting data from invoices or other financial documents can streamline accounting processes and reduce the chance of human error while enhancing business efficiency.
Need any of these solved? Nanonets can do these use cases and more. Solve your document data extraction issues with Nanonets today. Start your free trial.
Challenges of OCR in Document Automation
Poor image quality
For Document OCR to recognize characters accurately and convert them into digital text, the image quality must be clear and distinct. However, sometimes the images that need to be converted are of low quality, which can lead to OCR inaccuracies.
Handwriting recognition
Since handwriting can vary greatly from person to person, OCR engines can often not accurately convert handwritten text to digital text. It can lead to inaccuracies in the final output.
Language recognition
Different languages have different character sets and writing styles. As a result, it can be difficult for OCR engines to identify and convert them into digital text accurately. It is more challenging when the document being scanned contains multiple languages.
Layout and formatting inconsistencies
Different documents may have variations in their layout and formatting, making it difficult for OCR engines to identify and interpret the document's different segments accurately.
Integration with other systems
For the Document OCR outputs to be utilized effectively in other systems, it needs to be seamlessly integrated with those systems. However, this can be a complex process, especially when dealing with legacy systems that may not be compatible with modern OCR technologies.
Skewed images
Skewed images can cause OCR engines to incorrectly identify characters or segments of text, leading to inaccuracies in the final output.
Best Practices for Efficient Document OCR Processes
To ensure efficient document OCR processes, it is vital to follow certain recommended practices. These practices guarantee higher accuracy rates, faster processing times, and reduced errors, thus leading to increased productivity in the long run. To avoid this, the following points can be considered for an efficient process.
Choosing the right OCR software and hardware
One of the main things is selecting the right OCR software and hardware that suits your specific needs. OCR software applications have different capabilities, features, and limitations.
So, choosing an OCR solution that caters to your business needs, including document volume, type, and format is essential.
Also, choosing the right OCR hardware that can handle the volume of documents to be processed is equally important.
Preparing documents for OCR processing
Preparing the documents prior to OCR processing is another important. It is to ensure that the documents are in the appropriate format, structure, and orientation for the OCR software to recognize the text accurately. This may involve procedures such as scanning, image processing, and file conversion.
Training the OCR system
OCR software requires proper training to recognize and capture the text accurately from the documents. Therefore, training the OCR software through sample documents to recognize different fonts, styles, languages, and formats before full deployment is essential. This training process will enhance the accuracy of results and improve the overall OCR process.
Testing and refining OCR processes
After installing the OCR software, it is important to continuously test and refine the OCR processes to ensure that it delivers the desired results. It involves performance monitoring, error analysis, and fine-tuning of OCR processes to cater to your needs.
Regular reviews of the OCR processes will ensure that the OCR system remains efficient and flexible, thus meeting your evolving business needs.
Integrating OCR with other systems
Integrating the OCR system with existing systems, data repositories, and business processes is crucial to enhancing end-to-end document management. It enables seamless document processing, data extraction, report generation, and analysis, enhancing efficiency and greater productivity.
Have an OCR use case in mind?
Nanonets OCR software is easy to use, set up and provides 95%+ OCR accuracy. Extract data from PDFs, images, emails, and more on autopilot.
Nanonets for Document OCR automation
Nanonets is AI-based online OCR software that extracts texts from images, PDFs, and any other kind of document with 95% accuracy. Nanonets works with all OS and can be integrated with 5000+ apps with easy API and Zapier integrations.
It does not have a desktop app, but it is very lightweight, and therefore, it can be used using any online browser without putting a load on your device.
Nanonets are primarily used to automate all manual data entry processes. So, using Nanonets, you can automate data extraction, document processing, and document verification processes to improve your efficiency.

Why choose Nanonets?
- Easy to use
- Free plans
- Free migration assistance - we do the heavy lifting for you.
- Modern User Interface - Intuitive interface
- No code platform
- 5000+ integrations
- 24x7 support for everyone
- Exhaustive training material
- Professional OCR services
- Cloud and On-premise hosting
Conclusion
The advancements in OCR technology have been revolutionary, making document management much more efficient and cost-effective for organizations. As technology continues to improve, OCR will become even more accurate and capable of recognizing handwriting and even images. The development of machine learning algorithms has already led to significant improvements in OCR, and we are expected to see continued advancements in this area.
Investing in the most up-to-date OCR technology is strongly recommended for organizations considering OCR implementation. Doing so will allow them to achieve the highest levels of accuracy and ensure that the implementation process runs smoothly.
Additionally, it is important to ensure that OCR implementation is aligned with organizational goals and is integrated with existing systems and processes. Organizations should also consider the training required for employees to effectively use OCR and the potential cost savings it can bring.


