











































How to convert scanned PDF to Word in 2024
You've just received a 50-page contract that needs to be reviewed, but there's a catch: it's a scanned PDF. You know it is going to be a daunting task ahead. There is no search function, no copy-paste, and no easy editing.
Retyping the entire document into a Word file or converting the scanned PDF into an editable one may take forever. What's the alternative? OCR, or Optical Character Recognition, is the answer.
Let's explore what OCR software is and how it can help you convert scanned PDFs into editable Word documents quickly and easily. We'll provide step-by-step instructions and share expert tips to help you achieve the best possible results.
Understanding OCR: What it is and how it works
(This section includes the definition of OCR, a step-by-step process of how it works, a comparison between regular PDFs and scanned PDFs, the importance of OCR in today's digital age, and an introduction to AI-powered OCR. Feel free to skip this section if you're already familiar with these concepts)
OCR allows you to extract text from images and scanned documents. It helps convert scanned PDFs into editable Word files.
Here's a step-by-step process of how OCR works:
- Scanning: The physical document is scanned using a scanner, camera, or a smartphone camera to create a digital image.
- Pre-processing: The scanned image is enhanced to improve its quality. This may include techniques like deskewing (correcting the alignment), despeckle (removing noise), and binarization (converting the image to black and white).
- Text recognition: The image is then analyzed by the OCR software, which uses pattern recognition algorithms to identify individual characters, numbers, and symbols. It breaks down the image into smaller components, such as lines, words, and characters, and compares them against a pre-existing database of patterns to recognize the text.
- Post-processing: The OCR software then performs post-processing tasks to improve the accuracy of the output. This may include correcting errors, removing irregularities, and formatting the text into a structured document.
- Output: Finally, the OCR software generates a machine-readable text file, such as a Word document or a searchable PDF, which can be easily edited, searched, and integrated into various business processes.
Let's take a look at the difference between regular PDFs and scanned PDFs:
| Regular PDFs | Scanned PDFs |
|---|---|
| Created from digital sources | Created from physical documents |
| Contains machine-readable text | Essentially just images of the pages |
| Can be easily edited and searched | Requires OCR to convert into editable text |
The importance of OCR in today's digital age cannot be overstated. By automating the process of converting scanned documents into editable formats, OCR helps businesses:
- Automate converting scanned documents and images into editable and searchable text.
- Eliminate the need for manual data entry and minimize the risk of errors and the associated costs of correcting them.
- Extract data from documents with a high degree of precision, reducing the risk of errors that can lead to costly mistakes or compliance issues.
- Quickly digitize and centralize their document management, making accessing and analyzing data easier.
- Scale document processing capabilities without the need for additional manual labor.
- Recognize text in multiple languages and even translate the content into a different language.
What is AI-powered OCR?
While traditional OCR relies on pre-defined rules and patterns to recognize text, AI-powered OCR takes it to the next level. By leveraging machine learning algorithms, these advanced systems can adapt to various fonts, styles, and layouts without breaking a sweat.
AI-powered OCR outperforms traditional systems in processing complex documents, including those with tables, graphs, and handwritten text. It delivers highly accurate results, saving hours of manual work. And the best part? By automatically extracting valuable insights from scanned documents, businesses can make informed and data-driven decisions.
Nanonets is a leading AI-powered OCR solution that can handle a wide range of documents, from simple contracts to complex invoices and receipts. Its intelligent algorithms can accurately extract text, tables, and key-value pairs from scanned PDFs, making it an ideal choice for businesses looking to automate their document processing workflows.
How to convert scanned PDF to Word documents online?
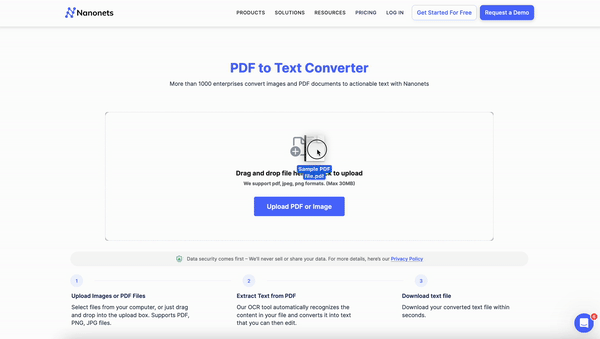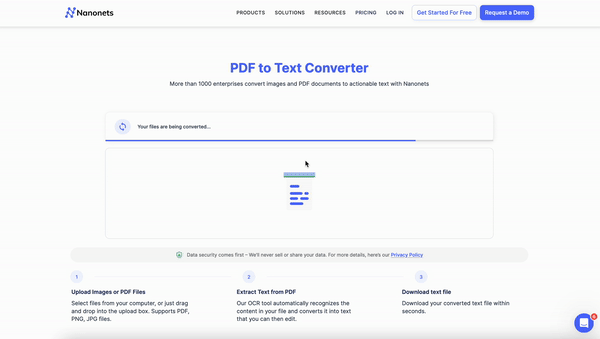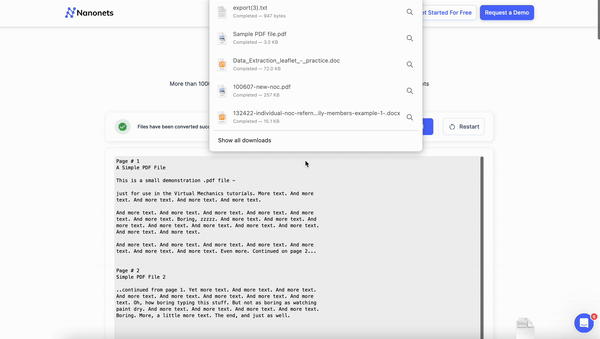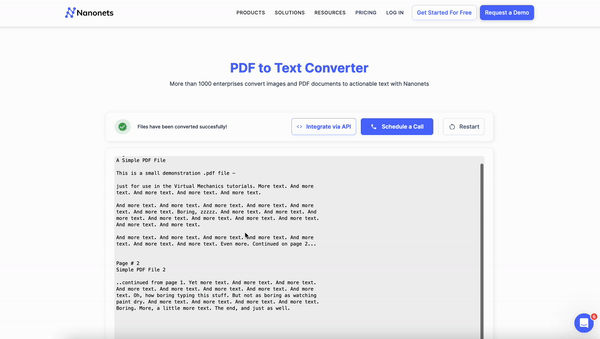
Nanonets offers a comprehensive solution for converting scanned PDFs to editable Word documents. With its advanced AI-powered OCR technology, intuitive interface, and versatile features, Nanonets streamlines your document workflow.
Here's a quick guide on how to use Nanonets for PDF to Word conversion:
Step 1: Document ingestion
You can upload your scanned PDFs to Nanonets in multiple ways.
a. Web upload: Go to the Nanonets PDF to Word Converter page and click "Upload File." Select the scanned PDF(s) you want to convert or drag and drop them into the upload area.
b. Email: To automatically process your scanned PDFs using Nanonets, Set up an auto-forwarding rule from your email to your unique Nanonets address to streamline the process. Nanonets will import and process the attached files using the specified model.
c. Google Drive: Connect your Drive, select the folder with scanned PDFs, and Nanonets will auto-import new files from that folder every 5 minutes, up to 3 folders deep.
d. Zapier: Connect Nanonets with over 5,000 apps using Zapier. Set up automated workflows to import scanned PDFs from various sources, such as Dropbox, OneDrive, or FTP, and have them processed by Nanonets.
e. API: Integrate Nanonets into your other business systems using its powerful API. It can automate sending scanned PDFs to Nanonets for conversion and retrieving the output in your desired format.
Step 2: OCR
Once your scanned PDFs are uploaded, Nanonets' advanced AI-powered OCR engine analyzes and extracts text, tables, and other document elements. The OCR technology is highly accurate and can handle various document layouts, languages, and even handwritten text. The extraction time depends on the file size and complexity but typically takes only a few seconds.
Step 3: Review and validation
After completing the OCR process, Nanonets provides a user-friendly interface to review the extracted data. You can easily verify the accuracy of the converted text, make any necessary corrections, and validate the output. This step ensures that your final Word document is error-free and matches the original scanned PDF.
Step 4: Data export and integration
Nanonets offers flexible options for exporting your converted data:
a. Download: Click "Download" to save the editable Word document(s) to your computer.
b. API: Retrieve the converted data programmatically through Nanonets' API, allowing seamless integration with your existing systems and workflows.
c. Cloud Storage: Automatically export the converted Word documents to popular cloud storage platforms like Google Drive, Dropbox, or OneDrive.
d. Third-Party Apps: Nanonets integrates with various third-party applications, such as Zapier, enabling you to automate document workflows and send the converted data to your preferred tools.
You'll be able to seamlessly incorporate the converted Word documents into your existing processes, saving time and effort. With Nanonets, you can streamline your document management, reduce manual data entry, and focus on more critical aspects of your business.

Alternative methods for converting scanned PDFs to Word
While Nanonets offers a comprehensive AI-powered solution for converting scanned PDFs to editable Word documents, several alternative methods are available. These include desktop OCR software, mobile scanning apps, online OCR tools, open-source tools, Python libraries, Microsoft Word's built-in OCR feature, and Adobe Acrobat Reader's PDF to Word feature.
1. Microsoft Word's built-in OCR feature
Microsoft Word now has a built-in OCR feature that allows users to convert scanned PDFs or images into editable Word documents directly within the application.
To use this feature, simply open a scanned PDF or image in Word, and the program will prompt you to convert the file using its built-in OCR.
Benefits:
- The workflow is straightforward
- No additional software installation required
Challenges:
- Limited control over OCR settings and output options
- It may not be as accurate as dedicated OCR software, especially for complex layouts or poor-quality scans
- Batch processing is not possible
2. Acrobat Reader's PDF to Word Export feature
Adobe Acrobat Reader Pro, the popular PDF viewer, includes a PDF-to-Word conversion feature that allows users to export scanned PDFs as editable Word documents.
To access the feature, open your scanned PDF in Adobe Acrobat Reader Pro, click on "Export a PDF" from "All Tools", and select DOCX as the export format.
Benefits:
- Seamless integration with the Adobe ecosystem
- Familiar interface for Adobe users
Challenges:
- You must be an Acrobat Pro subscriber to access the feature and the subscription is priced at US$19.99/mo.
- Limited control over OCR settings and output options compared to dedicated OCR software
- Batch processing is not possible without additional automation
3. Desktop OCR software
Desktop OCR software programs are installed directly on your computer, offering more control over the conversion process and output settings. These tools often include advanced features like batch processing, document editing, and support for multiple languages.
Top examples of desktop OCR software include:
- ABBYY FineReader
- FileCenter
- Readiris
- PaperScan Scanner
Benefits:
- More control over the OCR process and output settings
- Can handle large volumes of documents offline
- Often includes advanced features like batch processing and document editing
Challenges:
- More expensive than online solutions
- Steeper learning curve
- Requires installation and is limited to the computer on which it's installed
4. Mobile OCR apps
Due to the improvement in mobile cameras and processing power, mobile OCR apps have become increasingly popular for on-the-go document scanning and conversion. These apps allow users to capture images of documents using their smartphone cameras and convert them into editable text or Word documents.
Top examples of mobile OCR apps include:
- Adobe Scan
- Office Lens
- CamScanner
Benefits:
- Convenient and accessible
- Often free or more affordable than desktop software
- Integrates with cloud storage for easy sharing and collaboration
Challenges:
- It may not be as accurate as desktop software, especially for complex layouts or poor-quality scans
- Limited control over OCR settings and output options
- Not suitable for large volumes of documents due to mobile device storage constraints
5. Online OCR tools
Online OCR tools are web-based services that allow you to convert scanned PDFs to Word without installing software. They are accessible from any device with an internet connection and are often free.
Top examples of online OCR tools include:
- OnlineOCR.net
- SmallPDF
- OCR Space
Benefits:
- Accessible from any device with an internet connection
- Often free or more affordable than desktop software
- Ideal for occasional or one-off conversions
Challenges:
- Requires an internet connection to function
- May have file size or page count limitations
- Privacy concerns, as documents are uploaded to third-party servers for processing
- Less control over OCR settings and output compared to desktop software
6. Open-source tools
Open-source OCR tools are freely available software that allows users to access and modify the source code. These tools are often developed and maintained by a community of developers, offering transparency and flexibility. Some open-source OCR tools, such as OCRmyPDF, are built using Python libraries like Tesseract. If you want to use Python for OCR, check out the Python libraries section below.
Top examples of open-source OCR tools include:
- GOCR
- CuneiForm
- docTR
- Ocrad
Benefits:
- Free to use and modify
- Transparent and flexible
Challenges:
- Steeper learning curve
- It may require more technical knowledge to set up and use effectively
- It may lack user-friendly interfaces and documentation
7. Python libraries
Python offers several libraries for OCR and document processing. These libraries allow developers to build custom OCR solutions and integrate them into their applications or workflows. Python libraries can be used to create custom OCR solutions or integrate OCR capabilities into other applications. Many open-source OCR tools covered in the previous section are also built using these libraries.
Top examples of Python libraries for OCR include:
- PyTesseract
- OCRmyPDF
Benefits:
- Allows for custom OCR solutions and integration with other tools
- Can be automated and scaled for large volumes of documents
- Offers flexibility and control over the OCR process
Challenges:
- Requires programming skills and technical knowledge
- It may have a steeper learning curve for non-technical users
- Requires setting up a development environment and managing dependencies
When choosing an alternative method for converting scanned PDFs to Word, evaluating your specific needs and considering factors such as accuracy, document complexity, batch processing requirements, and customization options is essential. While these alternatives can be helpful in certain situations, they may have limitations compared to AI-powered OCR solutions like Nanonets.
Tips and tricks to achieve optimal scanned PDF to Word results
Nobody wants to spend hours and hours manually editing and formatting converted documents. To ensure the best possible results when converting scanned PDFs to Word, consider the following tips and tricks:
Scanning stage
- Use a high-quality scanner with a resolution of at least 300 DPI for text-based documents and 600 DPI for documents with images or complex layouts.
- Ensure the scanner glass is clean and free from smudges or dirt to avoid image quality issues.
- Align the document properly on the scanner bed to prevent skewed or crooked scans.
- Use the scanner's automatic document feeder (ADF) for multi-page documents to save time and ensure consistent alignment.
- Scan in grayscale or black and white for text-based documents to reduce file size. Use color only when necessary.
- Enable blank page detection to remove any empty pages from the scanned document.
- Use a scanning app with built-in image enhancement features, such as Office Lens or Adobe Scan, to automatically optimize the scanned image for better OCR results. These apps can correct perspective, adjust contrast, and remove shadows, making the conversion process smoother.
Pre-processing stage
- Organize and prepare the documents before scanning. Remove staples, paperclips, or sticky notes that may obstruct the text or cause scanning issues.
- If you need to scan old, fragile documents or photographs, consider using a flatbed scanner with a high resolution (600 DPI or more). Place the document on the scanner glass carefully and use a soft, lint-free cloth to smooth out any creases or folds gently.
- Use a contrasting background, such as a white sheet of paper, behind the document to help the scanner detect the edges accurately.
- For delicate or fragile documents, consider using a flatbed scanner instead of an ADF to minimize the risk of damage.
OCR and conversion stage
- Set up automated ingestion workflow to ensure consistent and efficient processing of large volumes of documents.
- Choose an OCR solution with high accuracy rates and support for multiple languages, such as Nanonets.
- Ensure the scanned document is of sufficient quality and resolution for accurate OCR results.
- Select the appropriate output format (e.g., .docx) and OCR settings (e.g., layout retention, language) based on your requirements.
- Verify the converted text and make necessary corrections using the OCR software's built-in editing tools.
Post-processing and export stage
- Review the converted Word document for any formatting inconsistencies or recognition errors.
- Adjust the document's layout, fonts, and styles to match your preferences or corporate branding guidelines.
- Use the built-in spell checker and grammar tools in Word to identify and correct any remaining errors.
- Save the final document in the desired format (e.g., .docx, .pdf) and optimize the file size for storage or sharing.
- Implement a consistent file naming convention and organize the converted documents in a logical folder structure for easy retrieval. For example, a financial institution could organize converted Word files by client name, document type, and date (e.g., "ClientX_TaxReturn_2023-04-15.docx").
- Use Zapier integrations to send the converted Word documents directly to your preferred business systems for further processing.

Why use Nanonets to convert Scanned PDF to Word?
Nanonets is AI-based OCR software that can extract text from PDFs with 98%+ accuracy. It’s easy to use, simple to set up (takes <15 minutes), and does the job perfectly.
You can use Nanonets PDF to word converter to:
- Process large PDF files instantly - Batch process hundreds of PDFs at once, saving hours of manual work.
- Extract text from scanned PDFs - Extract handwritten text, numbers, or text from scanned PDFs.
- Convert OCR PDF to Word - Handle scanned PDFs with ease, making it a reliable OCR PDF to Word converter.
- Multi-language support - Extract data and text from scanned PDFs in over 40+ languages.
Is Nanonets PDF to Word free to use?
Yes, Nanonets PDF to Word is completely free to use. You can extract data from scanned PDFs for free. You can also create a free account on Nanonets to use no-code workflows to automate repetitive tasks like document upload, pre-processing, data entry, and more.
Apart from this, on your free trial, you can extract barcodes, handwritten text, tables, metadata, and more from your Scanned PDFs. You can also use Nanonets to extract data from other types of documents like images, emails, invoices, receipts, and more.

Nanonets - Enterprise PDF processing platform
Nanonets provides completely customized solutions for enterprises looking to convert scanned PDF to Word documents on a large scale. If you have any questions, feel free to contact our team.
Nanonets can automate any kind of manual PDF process:
- PDF data extraction,
- View/Edit or Remove PDF Metadata,
- Document Archiving,
- Document Approvals
- Merge, Split, or rearrange PDF pages,
- Zonal OCR
- Converting handwritten documents to text,
And more.
Nanonets is an online OCR software; therefore, you can use all the features from your browser without downloading anything.

It is a perfect option for businesses of all sizes looking to optimize their document processes. Apart from these, here are some reasons to go for Nanonets as your next PDF processing platform:
- 1 Day Setup
- Free Migration Assistance
- Free Trial
- 24x7 Support
- No-code intelligent automation
- The dedicated customer success manager
- Cloud and On-premise hosting
- SOC2 and GDPR compliance platform
- Automated Audit Trail
- Automated Payments Platform
- 5000+ integrations
- Trusted by 500+ enterprises
- Works with 200+ Languages
- No post-processing required
Nanonets provides completely customized solutions for enterprises looking to convert scanned PDF to Word documents on a large scale. If you have any queries, feel free to reach out to our team.
Final thoughts
Converting scanned PDFs to editable Word documents doesn't have to be a hassle. Whether you're dealing with invoices, contracts, or any other type of scanned document, embracing the right tools and techniques can significantly improve your productivity and streamline your workflow.
If you want to automate your document conversion process on a larger scale, consider using an AI-powered platform like Nanonets. With features like bulk document conversion, advanced OCR technology, and seamless integrations, Nanonets can help you efficiently convert scanned PDFs to editable formats while maintaining the original layout and formatting.

Read more:
- How to convert PDF images to text?
- How to convert scanned PDF to word online for free?
- How to convert PDF to word?
- How to convert PDF to word on Mac?
Scanned PDF to Word workflow FAQs
How do I convert a scanned PDF to editable?
You can use Nanonets PDF to word tool to make your scanned PDFs editable in 4 steps. Open Nanonets PDF to Word tool > Upload your files> Click Convert> Download your text file.
Can I convert scanned PDF to word?
Yes, you can convert scanned PDF to word using Nanonets PDF to text tool. Simply open Nanonets PDF to text tool> Upload your PDF file> Click Convert and Download your text file. Nanonets will convert your PDF into editable text format in seconds.
How can I extract text from a scanned PDF?
You can use OCR software, like Nanonets, to convert text from a scanned PDF into text format that can be edited easily. Simple use Nanonets PDF to text converter tool. Upload your scanned PDF to convert it into text. It also converts handwritten text into editable digital text.
How do I convert a scanned document to text?
Using an online PDF-to-text OCR tool, you can convert a scanned document to text. Online OCR tools, like Nanonets PDF to text can convert scanned PDFs containing text or handwritten text into txt format.
Can I convert a scanned PDF to Word without losing formatting?
Yes, Nanonets' AI-powered scanned PDF-to-Word converter is designed to preserve the original formatting of your scanned document. It ensures that your document's layout, structure, and appearance remain intact during the conversion process.
Is there an AI-powered scanned PDF-to-Word converter?
Yes, Nanonets is an AI-powered scanned PDF-to-Word converter. It leverages advanced machine learning algorithms to accurately recognize and extract text from scanned PDFs, making the conversion process more efficient and precise than traditional OCR methods.


