













































Web Scraping with Python Tutorial
Suppose you want to scrape competitor websites for their pricing page information. What will you do? Copy-pasting or entering data manually is too slow, time-consuming, and error-prone. You can automate it easily using Python.
In this blog, we'll learn how to scrape webpages using Python.
What are the different Python web scraping libraries?
Python is popular for web scraping owing to the abundance of third-party libraries that can scrap complex HTML structures, parse text, and interact with HTML form. Here, we’ve listed some top Python web scraping libraries.
- Urllib3 is a powerful HTTP client library for Python. This makes it easy to perform HTTP requests programmatically. It handles HTTP headers, retries, redirects, and other low-level details, making it an excellent library for web scraping. It also supports SSL verification, connection pooling, and proxying.
- BeautifulSoup allows you to parse HTML and XML documents. Using API, you can easily navigate through the HTML document tree and extract tags, meta titles, attributes, text, and other content. BeautifulSoup is also known for its robust error handling.
- MechanicalSoup automates the interaction between a web browser and a website efficiently. It provides a high-level API for web scraping that simulates human behavior. With MechanicalSoup, you can interact with HTML forms, click buttons, and interact with elements like a real user.
- Requests is a simple yet powerful Python library for making HTTP requests. It is designed to be easy to use and intuitive, with a clean and consistent API. With Requests, you can easily send GET and POST requests, and handle cookies, authentication, and other HTTP features. It is also widely used in web scraping due to its simplicity and ease of use.
- Selenium allows you to automate web browsers such as Chrome, Firefox, and Safari and simulate human interaction with websites. You can click buttons, fill out forms, scroll pages, and perform other actions. It is also used for testing web applications and automating repetitive tasks.
- Pandas allow storing and manipulating data in various formats, including CSV, Excel, JSON, and SQL databases. Using Pandas, you can easily clean, transform, and analyze data extracted from websites.
Extract text from any webpage in just one click. Head over to Nanonets website scraper, Add the URL and click "Scrape," and download the webpage text as a file instantly. Try it for free now.
How to scrape data from websites using Python?
Let’s take a look at the step-by-step process of using Python to scrape website data.
Step 1: Choose the Website and Webpage URL
The first step is to select the website you want to scrape. For this particular tutorial, let’s scrape https://www.imdb.com/. We will try to extract data on the top-rated movies on the website.
Step 2: Inspect the website
Now the next step is to understand the website structure. Understand what the attributes of the elements that are of your interest are. Right-click on the website to select “Inspect”. This will open the HTML code. Use the inspector tool to see the name of all the elements to use in the code.
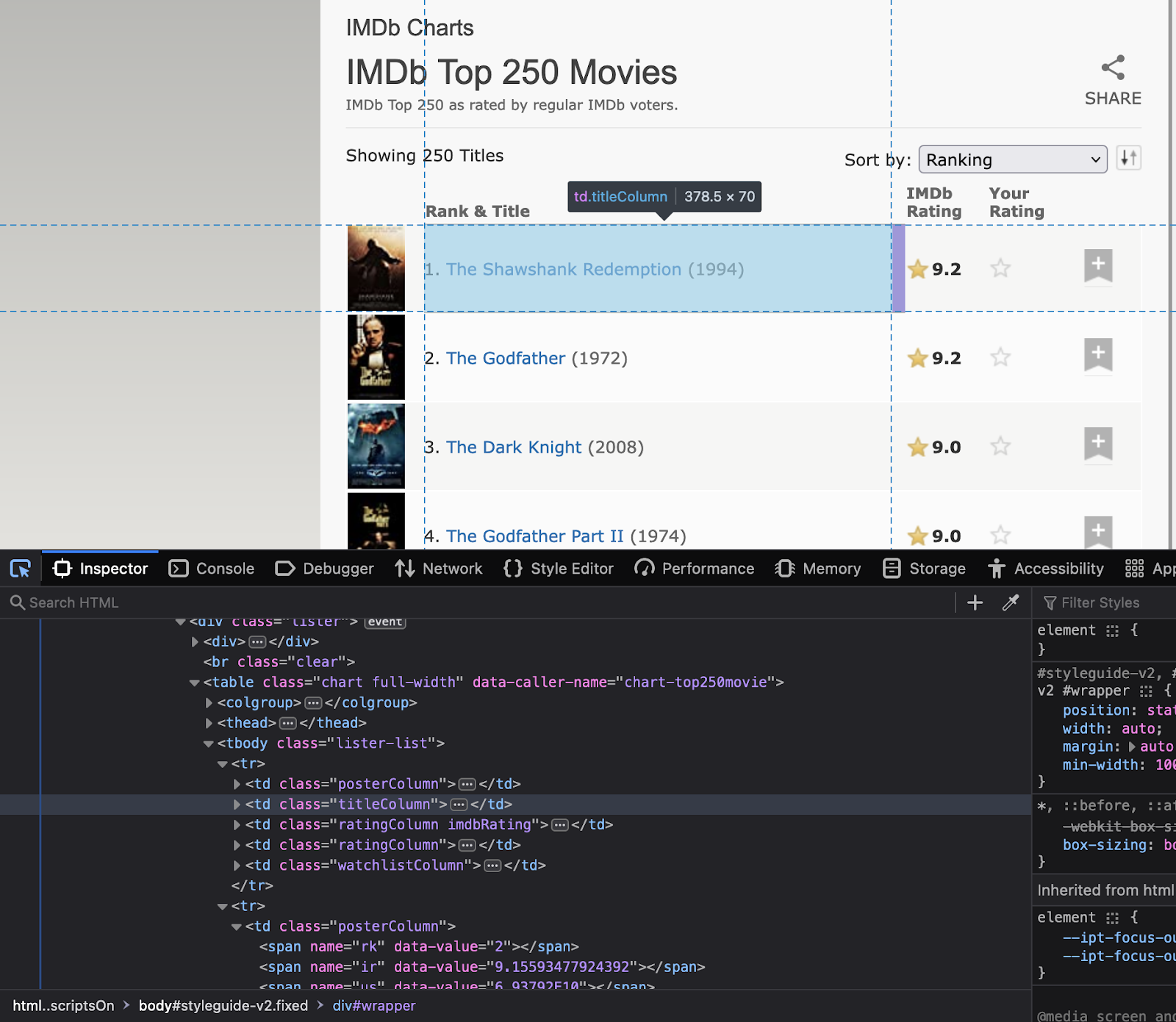
Note these elements' class names and ids as they will be used in the Python code.
Step 3: Installing the important libraries
As discussed earlier, Python has several web scraping libraries. Today, we will use the following libraries:
- requests - for making HTTP requests to the website
- BeautifulSoup - for parsing the HTML code
- pandas - for storing the scraped data in a data frame
- time - for adding a delay between requests to avoid overwhelming the website with requests
Install the libraries using the following command
pip install requests beautifulsoup4 pandas timeStep 4: Write the Python code
Now, it’s time to write the main python code. The code will perform the following steps:
- Using requests to send an HTTP GET request
- Using BeautifulSoup to parse the HTML code
- Extracting the required data from the HTML code
- Store the information in a pandas dataframe
- Add a delay between requests to avoid overwhelming the website with requests
Here's the Python code to scrape the top-rated movies from IMDb:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# URL of the website to scrape
url = "https://www.imdb.com/chart/top"
# Send an HTTP GET request to the website
response = requests.get(url)
# Parse the HTML code using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the relevant information from the HTML code
movies = []
for row in soup.select('tbody.lister-list tr'):
title = row.find('td', class_='titleColumn').find('a').get_text()
year = row.find('td', class_='titleColumn').find('span', class_='secondaryInfo').get_text()[1:-1]
rating = row.find('td', class_='ratingColumn imdbRating').find('strong').get_text()
movies.append([title, year, rating])
# Store the information in a pandas dataframe
df = pd.DataFrame(movies, columns=['Title', 'Year', 'Rating'])
# Add a delay between requests to avoid overwhelming the website with requests
time.sleep(1)Step 5: Exporting the extracted data
Now, let’s export the data as a CSV file. We will use the pandas library.
# Export the data to a CSV file
df.to_csv('top-rated-movies.csv', index=False)Step 6: Verify the extracted data
Open the CSV file to verify that the data has been successfully scraped and stored.
We hope this tutorial will help you extract data from webpages easily.
While discussing the intricacies of web scraping with Python, it's clear that handling massive amounts of data can be overwhelming. This is where Nanonets steps in to streamline your processes. Imagine automating the tedious task of data extraction with our cutting-edge Workflows Automation platform. Not only does it integrate seamlessly with your apps, but it also utilizes AI to enhance workflows, making your projects error-free and efficient. Ready to revolutionize your data handling? Dive into the future of automation with us.
How to parse text from the website?
You can parse website text easily using BeautifulSoup or lxml. Here are the steps involved along with the code.
- We will send an HTTP request to the URL and get the webpage's HTML content.
- Once you have the HTMl structure, we will use BeautifulSoup's find() method to locate a specific HTML tag or attribute.
- And then extract the text content with the text attribute.
Here's a code of how to parse text from a website using BeautifulSoup:
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access
response = requests.get("https://www.example.com")
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the text content of the webpage
text = soup.get_text()
print(text)How to scrape HTML forms using Python?
To scrape HTML forms using Python, you can use a library such as BeautifulSoup, lxml, or mechanize. Here are the general steps:
- Send an HTTP request to the URL of the webpage with the form you want to scrape. The server responds to the request by returning the HTML content of the webpage.
- Once you have accessed the HTML content, you can use an HTML parser to locate the form you want to scrape. For example, you can use BeautifulSoup's find() method to locate the form tag.
- Once you have located the form, you can extract the input fields and their corresponding values using the HTML parser. For example, you can use BeautifulSoup's find_all() method to locate all input tags within the form, and then extract their name and value attributes.
- You can then use this data to submit the form or perform further data processing.
Here's an example of how to scrape an HTML form using mechanize:
import mechanize
# Create a mechanize browser object
browser = mechanize.Browser()
# Send an HTTP request to the URL of the webpage with the form you want to scrape
browser.open("https://www.example.com/form")
# Select the form to scrape
browser.select_form(nr=0)
# Extract the input fields and their corresponding values
for control in browser.form.controls:
print(control.name, control.value)
# Submit the form
browser.submit()Extract text from any webpage in just one click. Head over to Nanonets website scraper, Add the URL and click "Scrape," and download the webpage text as a file instantly. Try it for free now.
Comparing all Python web scraping libraries
Let’s compare all the python web scraping libraries. All of them have excellent community support, but they differ in ease of use and their use cases, as mentioned in the start of the blog.
Conclusion
Python is an excellent option for scraping website data in real-time. Another alternative is to use automated website scraping tools like Nanonets. You can use the free website-to-text tool. But, if you need to automate web scraping for larger projects, you can contact Nanonets.
Extract text from any webpage in just one click. Head over to Nanonets website scraper, Add the URL and click "Scrape," and download the webpage text as a file instantly. Try it for free now.
FAQs
How to use HTML parser for web scraping using Python?
To use an HTML parser for web scraping in Python, you can use a library such as BeautifulSoup or lxml. Here are the general steps:
- Send an HTTP request to the URL of the webpage you want to access. The server responds to the request by returning the HTML content of the webpage.
- Once you have accessed the HTML content, you can use an HTML parser to extract the data you need. For example, you can use BeautifulSoup's find() method to locate a specific HTML tag or attribute, and then extract the text content with the text attribute.
Here's an example of how to use BeautifulSoup for web scraping:
python
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access
response = requests.get("https://www.example.com")
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract specific data from the webpage
title = soup.title
print(title)
In this example, we use BeautifulSoup to parse the HTML content of the webpage and extract the title of the page using the title attribute.
Why is Web Scraping Used?
Web scraping is used to scrape website data using automated tools or scripts. It can be used for multiple purposes
- Extracting data from multiple webpages and aggregating the data to do further analysis.
- Deriving trends by scraping real-time data on various time stamps.
- Monitoring competitor pricing trends.
- Generating leads by scraping emails from websites.
What Is Web Scraping?
Web scraping I used to extract structured data from unstructured HTML websites. Web scraping involves using automated web scraping tools or scripts to parse complex web pages.
Is Web Scraping Legal?
Web scraping is legal when you’re trying to parse publicly available data on a website. In general, web scraping for personal use or non-commercial purposes is legal. However, scraping data that is protected by copyright or is considered confidential or private can lead to legal issues.
In some cases, web scraping may violate the terms of service of a website. Many websites include terms that prohibit automated scraping of their content. If a website owner discovers that someone is scraping their content, they may take legal action to stop it.
Why is Python Good For Web Scraping?
Python is a popular programming language for web scraping because it offers several advantages:
- Python has a simple and readable syntax and is easy for beginners to learn.
- Python has a huge community of developers that develop tools for various tasks like web scraping.
- Python has many web scraping libraries like Beautiful Soup and Scrapy.
- Python can do a lot of tasks like scraping, extracting website data to excel, interacting with HTML forms, and more.
- Python is scalable, making it suitable for scraping large volumes of data.
What is an example of web scraping?
Web scraping is extracting data from web pages using automated scripts or tools. For example, web scraping is used to scrape emails from websites for lead generation. Another web scraping example is extracting competitor pricing information to improve your pricing structure.
Does web scraping need coding?
Web scraping converts unstructured website data into a structured format. Apart from using coding to scrape websites, you can use completely no-code web scraping tools which require no coding at all.


