













































AWS Textract Teardown - Pros and Cons of using Amazon's Textract in 2023
Text Recognition in 2023
In many companies and organizations, plenty of valuable business data is stored in documents. This data is at the heart of digital transformation. Unfortunately, according to statistics, 80% of all this data is embedded in unstructured formats like business invoices, customer orders, emails, receipts, PDF documents, and many more. Therefore, to extract and make the most out of information from these documents, companies slowly started relying on Artificial intelligence (AI) based services. Out of those that provide AI-based services, Amazon had been one of the most prominent players for a long time. It had its wings spread across different solutions like document processing, speech recognition, text analytics, and much more.
In this blog, we'll be looking at Amazon's AWS Textract, a fully managed machine learning service that automatically extracts printed text, handwriting, tables, and other data from scanned documents. Let’s get started!
What is AWS Textract?
In simple terms, AWS Textract is a deep learning-based service that converts different types of documents into an editable format. Consider we have hard copies of invoices from different companies and store all the vital information from them on excel/spreadsheets. Usually, we rely on data entry operators to manually enter them, which is hectic, time-consuming, and error-prone. But using Textract, all we need to do is upload our invoices to it and in turn, it returns all the text, forms, key-value pairs, and tables in the documents in a more structured way. Below is a screenshot of how AWS does intelligent information extraction:
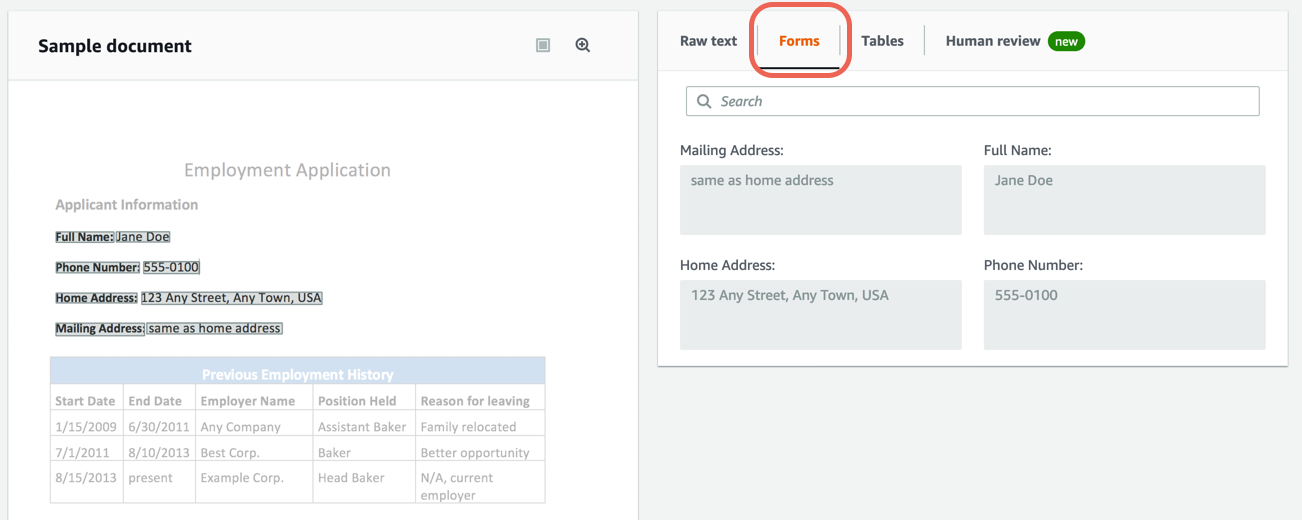
Not just typed text, AWS Textract also identifies handwritten texts in the documents. This makes information extraction more useful, as in some cases extracting handwritten text is more complicated to extract than typed ones. Now let’s see some of the common use cases for using Textract:
Robust and Normalised Data Capture: Amazon Textract enables text and tabular data extraction from a wide variety of documents, such as financial documents, research reports, and medical notes. However, these are not custom-made APIs, but they learn from a vast amount of data every day, and with this continuous learning, extracting unstructured and structured data from your document will be much easier.
Key-Value Pair Extraction: Key-Value pair extraction has become a common problem for document processing but with Amazon Textract this can be easily solved. We can build pipelines for key-value pair extraction using Textract which automates document processing right from scanning documents to pushing data to excel sheets etc.
Creating an intelligent search index: Amazon Textract enables you to create libraries of text detected in image and PDF files.
Using intelligent text extraction for Natural Language Processing (NLP) – Amazon Textract enables you to extract text into words and lines. It also groups text by table cells if Amazon Textract document table analysis is enabled. Amazon Textract provides you with control over how text is grouped as input for NLP.
Looking for an intelligent Text Recognition solution? Head over to Nanonets and use the solution with accuracy above 95% .
How AWS Textract Works?
In this section, we'll be discussing how AWS Textract works. We know that strong AI and ML algorithms are behind them; however, there aren't any open-source models to dive into the specifics. But I'll try to decode the workings by summarising the documentation that can be found here. Let’s get started!

Firstly, whenever a new or a scanned document is sent into Textract, it creates a list of block objects for all the detected text. For example, say an invoice consists of hundred words today, AWS makes hundred block objects for all the words. These blocks contain information about a detected item, where it's located, and the confidence that Amazon Textract has in the accuracy of the processing.
Usually, most of the documents are made of the following blocks:
- Page
- Lines and words of text
- Form data (Key-value pairs)
- Tables and Cells
- Selection elements
Below is an example and the block data structure of AWS Textract:
{
"Blocks":[
{
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Top": 0.0,
"Left": 0.0,
"Height": 1.0
},
"Polygon": [
{
"Y": 0.0,
"X": 0.0
},
{
"Y": 0.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 0.0
}
]
},
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"2602b0a6-20e3-4e6e-9e46-3be57fd0844b",
"82aedd57-187f-43dd-9eb1-4f312ca30042",
"52be1777-53f7-42f6-a7cf-6d09bdc15a30",
"7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c"
]
}
],
"BlockType": "PAGE",
"Id": "8136b2dc-37c1-4300-a9da-6ed8b276ea97"
}.....
],
"DocumentMetadata": {
"Pages": 1
}
}
However, the content inside the blocks changes based on the operation we call. For the text detection operation, the blocks return the pages, lines, and words of detected text. If we’re using the document analysis operations the blocks will return the detected pages, key-value pairs, tables, selection elements, and text. However, this only explains the higher-level working of Textract, in the next section let’s dive into OCR behind Textract.
Textract OCR
There are no specifics regarding the type of OCR Amazon Textract uses as it's a commercial product. However, we can compare it to one of the most popular open-source OCR, "Tesseract", to understand its accuracy and capability to extract various types of documents.
Tesseract OCR is based on LSTM, a deep learning-based neural network architecture that performs exceptionally well on text data. Following are the formats of documents that tesseract supports: plain text, hOCR (HTML), PDF, invisible-text-only PDF, TSV. It has Unicode (UTF-8) support and supports more than 100 languages out of the box. However, as all the code is open-source, it can be trained to recognize other languages, but this requires deep learning and computer vision expertise. When it comes to the table and key-value pair extraction, tesseract fails. Still, we can build custom pipelines to solve this problem.
Textract OCR is also a deep learning-based neural network architecture, but this cannot be completely customizable or trained on a custom dataset. Its job is to parse and extract all the data that's inside a document. However, Textract automatically tunes to your data and achieves higher accuracy on the go if a human verifies the extracted information (human in the loop). For tasks like table extraction and key-value pair extraction, Textract does a fair job achieving higher accuracy than Tesseract. But it's limited only to a few languages and document formats.
Below are some of the document types that can be processed using AWS Textract:
- Regular Invoices / Bills
- Financial Documents
- Medical Documents
- Handwritten Documents
- Payslips or Employee Documents
In the next section, let’s look at the Textract Python API.
Looking for an intelligent OCR solution to extract information from your documents? Head over to Nanonets to extract text from documents in any format in any language.
Textract Python API
Amazon Textract API can be utilized in various programming languages. In this section, we'll be looking at a code-block of key-value extraction using Textract with Python. For more information on language and API support do check out the docs here.
This code snippet is an example of how we can perform key-value pair extraction on documents utilizing Textract’s Python API. To get this working, we’ll have to also configure API key’s on the AWS dashboard. Now let’s dive into the code snippet,
Firstly, we import all the necessary packages for pushing documents to AWS and processing the extracted text.
import boto3
import sys
import re
import json
Next, we have a function named get_kv_map, in here we use boto3 to communicate with the Amazon Textract API, upload the document, and fetch the block response. We now get all the key-value pairs by checking the 'BlockType' and return it in dictionaries.
def get_kv_map(file_name):
with open(file_name, 'rb') as file:
img_test = file.read()
bytes_test = bytearray(img_test)
print('Image loaded', file_name)
# process using image bytes
client = boto3.client('textract')
response = client.analyze_document(Document={'Bytes': bytes_test}, FeatureTypes=['FORMS'])
# Get the text blocks
blocks=response['Blocks']
# get key and value maps
key_map = {}
value_map = {}
block_map = {}
for block in blocks:
block_id = block['Id']
block_map[block_id] = block
if block['BlockType'] == "KEY_VALUE_SET":
if 'KEY' in block['EntityTypes']:
key_map[block_id] = block
else:
value_map[block_id] = block
return key_map, value_map, block_map
After that, we have a function that gets the relationship between the extracted key-value pairs using the block items. Basically, using the relationships present in the block information (JSON) this function associates the keys and values in the document.
def get_kv_relationship(key_map, value_map, block_map):
kvs = {}
for block_id, key_block in key_map.items():
value_block = find_value_block(key_block, value_map)
key = get_text(key_block, block_map)
val = get_text(value_block, block_map)
kvs[key] = val
return kvs
def find_value_block(key_block, value_map):
for relationship in key_block['Relationships']:
if relationship['Type'] == 'VALUE':
for value_id in relationship['Ids']:
value_block = value_map[value_id]
return value_block
Lastly, we return the text present in the saved key-value pairs.
def get_text(result, blocks_map):
text = ''
if 'Relationships' in result:
for relationship in result['Relationships']:
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
word = blocks_map[child_id]
if word['BlockType'] == 'WORD':
text += word['Text'] + ' '
if word['BlockType'] == 'SELECTION_ELEMENT':
if word['SelectionStatus'] == 'SELECTED':
text += 'X'
return text
def print_kvs(kvs):
for key, value in kvs.items():
print(key, ":", value)
def search_value(kvs, search_key):
for key, value in kvs.items():
if re.search(search_key, key, re.IGNORECASE):
return value
def main(file_name):
key_map, value_map, block_map = get_kv_map(file_name)
# Get Key Value relationship
kvs = get_kv_relationship(key_map, value_map, block_map)
print("\n\n== FOUND KEY : VALUE pairs ===\n")
print_kvs(kvs)
# Start searching a key value
while input('\n Do you want to search a value for a key? (enter "n" for exit) ') != 'n':
search_key = input('\n Enter a search key:')
print('The value is:', search_value(kvs, search_key))
if __name__ == "__main__":
file_name = sys.argv[1]
main(file_name)
In this way, we can use the AWS Textract API to perform different information extraction tasks. The functions/approach is similar to most of the programming languages. We can also customize the approach based on our use cases if we’re to utilize the APIs.
Want to automate data entry from documents? Nanonets' AI based OCR solution can help extract key information from structured/unstructured documents and put the process on auto-pilot!
Pros and Cons of using AWS Textract
Pros:
Easy Setup with AWS Services: Setting up Textract with another AWS service is an easy task compared to other providers. For example, storing extracted document information with Amazon DynamoDB or S3 can be done by configuring an add-on.
Secure: Amazon Textract conforms to the AWS shared responsibility model, which includes regulations and guidelines for data protection. AWS is responsible for protecting the global infrastructure that runs all the AWS services; therefore we need not worry about our data being leaked or used by any others.
Cons:
Inability to Extract Custom Fields: There could be multiple data fields in a given invoice, say Invoice ID, Due Date, Transaction Date etc. These fields are something that are common in most invoices. But if we want to extract a custom field from an invoice, say, GST number or bank information, Textract does a poor job.
Integrations with upstream and downstream providers: Textract doesn't allow you to integrate with different providers easily, say, for example, we'll have to build an RPA pipeline with a third-party service; it would be difficult to find appropriate plugins that suit Textract.
Ability to define table headers: For table extraction tasks, textract doesn't allow you to define table headers. Therefore, it would be not easy to search or find a particular column or a table in a given document.
No Fraud Checks: Modern OCRs are now able to find if a given document is original or fake by validating dates and finding pixelated regions. AWS Textract doesn’t come with this, its only job is to pick all the text from an uploaded document.
No Vertical Text Extraction: In some of the documents, invoice numbers or addresses can be found in a vertical alignment. At present, AWS only supports horizontal text extraction with a slight in-plane rotation.
Language Limit: Amazon Textract supports English, Spanish, German, French, Italian, and Portuguese text detection. Amazon Textract will not return the language detected in its output.
Everything’s Cloud: Any document processed with Textract goes into the cloud, only supporting a few regions. More information here. However, some companies might not be interested in taking their documents to the cloud for reasons like confidentiality or legal requirements. Still, unfortunately, AWS Textract does not support any on-premise deployment for document processing.
Retraining: If our accuracy is low on information extraction tasks for a set of documents, Textract doesn't allow us to re-train them. To resolve this, we'll have to again invest in a human review workflow, where an operator has to manually verify and annotate wrongly extracted values, which is again time consuming.
Conclusion
We hope this review of AWS Textract has been useful as you consider different solutions for data extraction/text recognition from your documents.
We have similar breakdowns if you are looking for review or alternatives for Kofax or Google Vision.
We'll keep updating this post periodically to cover latest changes. For more details on OCR software here's a detailed review of the top OCR solutions available in the market today.
Please add your thoughts and questions about using Amazon's Textract solution in the comments section.
Source: Hero image from AWS website.


