













































ABBYY Teardown - Pros and Cons of using ABBYY
ABBYY is a global technology company that provides solutions for document processing, data capture, and language-based technologies. It was founded in 1989 by a group of linguists and engineers from Moscow State University. The company's name is an acronym for "Advanced Business Computer Systems."
ABBYY's first products were dictionaries and linguistic software for different markets. In the 1990s, ABBYY expanded its product line to include optical character recognition (OCR) and document scanning apps. ABBYY's PDF products are some of the most popular on the market. More than 100 million people use ABBYY PDF products every day. The company strives to provide accurate, reliable, and user-friendly solutions that everyone can use, from individuals to large organizations.
This blog post will overview their product line and some pros/cons of working together. We'll also compare some of their products with those offered by other top-notch companies in this industry so that you can decide whether they would be the right fit for your needs.
Let’s dive in.
What solutions does ABBYY offer?
ABBYY offers a complete range of OCR and PDF conversion and editing software that is easy to use and reliable. Their products allow users to convert documents into searchable PDFs, edit PDFs and extract data from forms and tables. The company also offers a mobile app for iOS and Android devices that allows users to scan and convert paper documents into digital formats. In this section, we'll explore the different services they provide.
ABBYY Vantage
ABBYY Vantage is a document management solution that allows you to automate your business processes with the help of smart algorithms and artificial intelligence. You can improve the efficiency of your workflow by using this tool to convert, annotate, process, and extract data from various documents. This tool also allows you to use OCR technology for various purposes such as document classification, indexing, and searching. ABBYY Vantage also offers data analytics capabilities to help companies track trends and gain new insights about their business.
ABBYY Timeline
ABBYY Timeline is an application for visualizing historical events from unstructured text documents such as news articles or emails. The tool allows users to see how concepts evolve and identify patterns in trends over time. Primarily, this application uses natural language processing techniques to identify events from text documents and then groups those events into timelines based on the type of event.
ABBYY FlexiCapture
ABBYY FlexiCapture is a software suite that helps organizations automatically capture key fields from paper forms into their databases or CRM systems. This tool can easily extract data from various forms, including invoices, purchase orders, bank statements, insurance claims, etc.
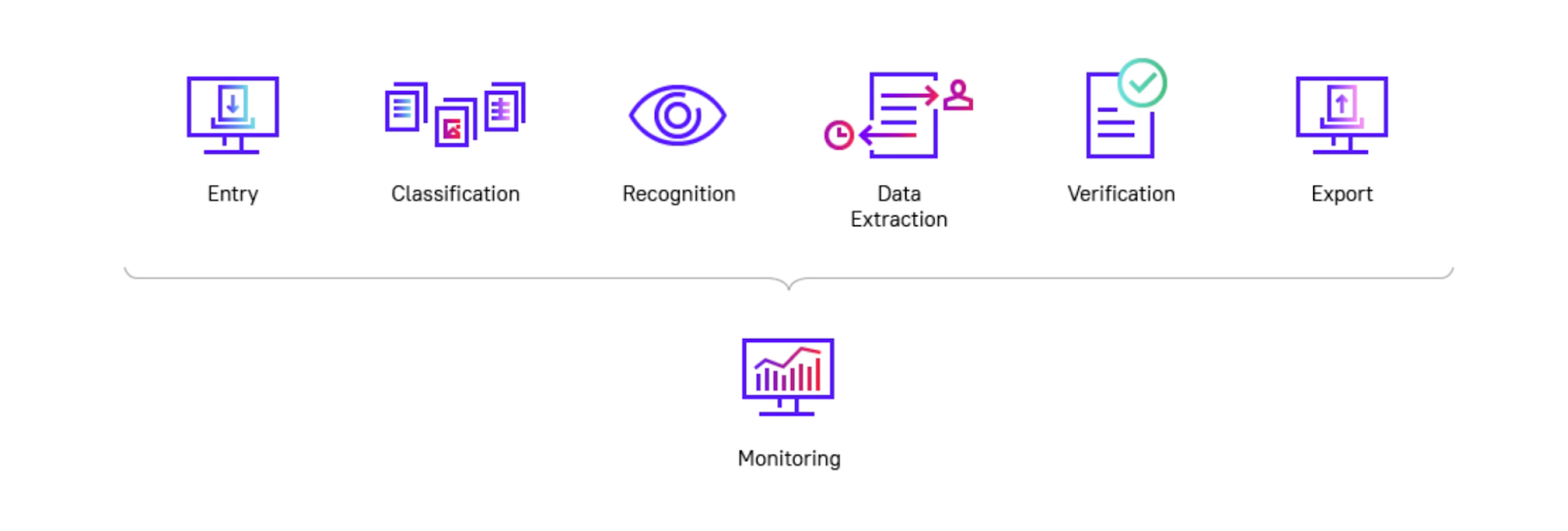
ABBYY FlexiCapture for Invoices
ABBYY FlexiCapture for Invoices is designed to help businesses streamline their invoice management processes by automating invoice processing tasks. This solution allows you to save time by automatically extracting, standardizing, and enriching data from invoices with additional information from your internal databases and creating customized reports based on your needs.
ABBYY FineReader Server
ABBYY FineReader Server is a solution for automated document conversion, indexing, and retrieval on the server side. It converts scanned documents into editable formats in real-time using OCR (optical character recognition) technology, thus allowing users to edit and reuse them as needed. The solution also offers advanced features such as fine-grained indexing for searchability and enhanced document analysis for a better understanding of the content structure among others.
The enterprise solutions from ABBYY are available to integrate with different systems through SDKs and developer tools.
ABBYY FlexiCapture and ABBYY FineReader are the two most popular services offered by ABBYY. Let’s take a closer look.
ABBYY FlexiCapture has many functions in common with ABBYY FineReader Server (formerly branded as Recognition Server). However, each product is designed with unique functions, which companies must consider when evaluating solutions to their document capture and OCR requirements. To help you compare the products more easily, we have compiled a list of use cases that will allow you to assess between ABBYY FlexiCapture and FineReader Server.
Looking for an intelligent Text Recognition solution? Head over to Nanonets and use the solution with accuracy above 95% .
What are the business use cases of ABBYY Finereader OCR?
ABBYY FineReader Server is a document-conversion program used to convert documents and images into searchable formats. The program operates on a server, enabling large-scale conversion of documents within a company's processing time frame. It can also provide a cost-effective means for companies to capture and manually index documents across the enterprise, either through scanning paper documents or processing electronic files and images. One drawback, however, is that it does not provide for the conversion of handwriting or check mark values [1].
In the image below, you can see the relationship between the components of the FineReader Server.
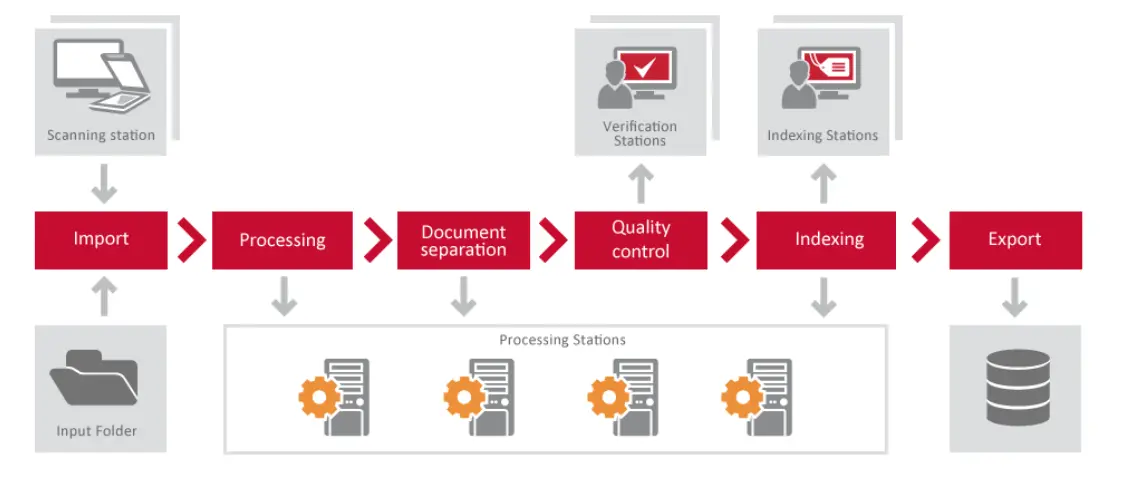
Some common use-cases
Bulk Processing
Monitor shared folders on a network and make image-to-text PDF conversions from images or documents. When a new file is added to a folder, it is converted to a text-searchable version and then moved to the corresponding export folder while maintaining the original sub-folder designation. The export file would maintain the legal integrity of the original image file while adding a searchable text layer behind the image in the PDF file in the export folders.
Document Scanning
When you scan documents into a digital format, you get the added benefit of being able to copy and paste text from those documents into other documents. However, you must manually retype the text if no OCR software is available. The time it takes to do this can be significant. FineReader OCR allows users to quickly convert scanned images into editable text files that can be easily accessed and manipulated in other applications, such as Word or Excel. The same goes for faxes, which are often received in TIFF format and don't support editing or manipulation. Using FineReader OCR, these faxes can be converted into editable PDF files or even word documents with a few clicks.
Documents Digitization (Images to Text)
ABBYY offers a data extraction solution that can be used to convert images of printed or handwritten text into an editable format. This is an important tool for businesses and organizations that need to digitize large volumes of documents, such as financial, legal, or medical. The data extraction process can automatically extract text from images, which can then be stored in a database or converted into a searchable PDF or another document format. This solution can save businesses and organizations significant time and money by reducing the need for manual data entry. In addition, the data extraction process can be used to improve the accuracy of data entry by providing a consistent and accurate method for converting paper documents into digital format.
Machine Translation
ABBYY FineReader OCR can be used as a machine translation tool by converting an image into text in another language (machine translation). This can be useful if you want to provide translation services without having to maintain human translators at your location but still want to provide quality translations to your customers (or simply don’t want to waste time translating something yourself).
Table Extraction
Table extraction is a process of extracting data from PDFs or images of table documents through the use of optical character recognition (OCR). It is commonly used to convert scanned paper documents, such as receipts, into a digital format so that the data can be processed, analyzed, and stored more efficiently. Various OCR software is available in the market, but ABBYY FineReader is one of the most popular choices. The technology can recognize lines and cells, and it can also detect headers and footers. It’s possible to process multi-page documents at once, which saves time. In addition, ABBYY FineReader supports a wide range of languages, making it ideal for extracting data from documents in different languages.
Want to automate data entry from documents? Nanonets' AI based OCR solution can help extract key information from structured/unstructured documents and put the process on auto-pilot!
What are the business use cases of Flexicapture OCR?
ABBYY FlexiCapture is primarily an enterprise-level data extraction software application that provides optical character recognition (OCR) functions. FlexiCapture provides a means to automatically extract information from documents based upon establishing rules, including keywords and the location of the data on a page. FlexiCapture is currently available in special, ready-to-run solution packages such as FlexiCapture for Invoices and FlexiCapture for Mailrooms. Although the solution heavily relies upon the use of the same OCR technology found within FineReader Server, and it can export a text-searchable version of a document if needed, its core functions are as follows:
- Classification of documents (determining their type)
- Matching these document classes to the corresponding data extraction rules
- Exporting the data somewhere such as a database, XML file or Microsoft Excel.
FlexiCapture's document classification capabilities can be used to extract and then compare field values from document sets. For example, a loan application may contain half a dozen documents, some of which contain an SSN. A rule can easily be configured to compare the SSNs from each document containing a value for this field and then present any errors to the operator during the document verification phase.
In the image below, you can see the relationship between the components of the FlexiCapture Server.
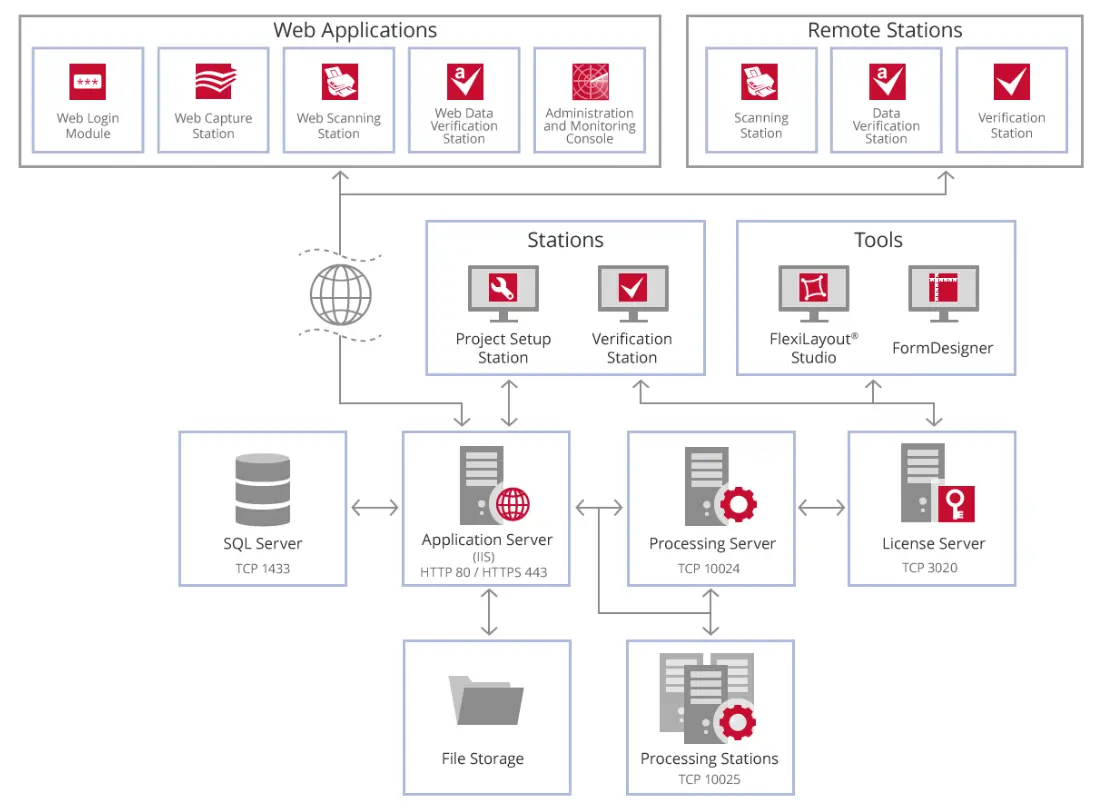
Some common use-cases
2-Way Matching
ABBYY FineReader has features that can help your accounts payable department run more smoothly. This includes:
- Automatic extraction of invoice data from paper and electronic documents
- 2-way matching of invoice line items against the corresponding purchase in the ERP system
- Searching through text-searchable invoices
- Approving payments by dollar amount or other rules
- Automated processing of incoming purchase orders
Document Classification
- Classify incoming documents by type and extract the data from the documents using rules that have been preconfigured.
- Export a text searchable PDF version of the document to a content management system and populate fields with data extracted from the document.
- Provide users with a means of correcting the extracted data along with queues for managing exceptions to pre-programmed rules within the document workflow process.
Top Alternatives for ABBYY Solutions
ABBYY vs. Amazon Textract

Amazon Textract is a service that automatically extracts text and data from scanned documents. It goes beyond simple optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables.
Amazon AWS Textract is a newer tool that is growing in popularity, thanks to its low cost and ease of use. It is ideal for scanning a large number of documents, although its accuracy levels are not quite as high as ABBYY [2].
The main difference between ABBYY and Amazon Textract is that while ABBYY provides a standalone solution for extracting text from images using Optical Character Recognition (OCR), Amazon provides its customers with an API they can integrate into their own applications. They even provide different SDKs, making it easier for developers to integrate this feature into their products; however, this requires additional knowledge about programming languages like Java or Python.
Furthermore, unlike AWS Textract, ABBYY provides absolute control over every aspect of your OCR process (for example, it allows you to customize word segmentation).
Both ABBYY and AWS Textract work very well in terms of accuracy and speed in most cases.
Pros of Textract
- You can use AWS Textract with any text-processing application with an SDK.
- AWS Textract supports more than 25 languages across 200 countries and territories. You can use it to translate your image files in real-time and create multilingual processing pipelines.
- This tool is cost-efficient. It costs only $0.0025 per 100,000 characters processed—less than half the cost of other solutions!
- AWS Textract is scalable, meaning you can use it on a large or small scale, depending on your needs.
Cons of Textract
- AWS Textract requires a lot of time and resources to train with your data before you can use it in production.
- Modern optical character recognition (OCR) software can identify if an uploaded document is original or a forgery by validating dates, finding pixelated regions, and other methods. AWS Textract does not have this capability; it can only extract text from an uploaded document.
- Textract doesn't allow integrations with upstream and downstream providers easily. For example, we may have to build an RPA pipeline with a third-party service. It would be difficult to find appropriate plugins that suit Textract.
ABBYY vs. Tesseract

Tesseract OCR was designed to recognize a wide range of languages written in pure C++ code. It can also be compiled for use on mobile devices such as Android and iOS platforms. The software uses advanced features such as vertical text layout detection, allowing users to read text from various angles without losing accuracy.
ABBYY and Tesseract provide OCR solutions and boast high accuracy rates and support a variety of languages. However, there are some critical differences between the two. ABBYY offers a more user-friendly interface, making it ideal for those new to OCR. It also provides more features, such as exporting multiple formats and performing image editing. On the other hand, Tesseract is open source and therefore free to use. It also has a more accurate engine, making it the better choice for those needing the highest possible accuracy level.
Pros of Tesseract
- It works with various languages in various fonts, including Roman, Cyrillic, Han Ideographic script, Hebrew, Arabic, and Thai.
- The source code is available under an Apache license, so it's free to use and modify. It also has a low memory footprint compared with other OCR engines, so it doesn't take up too much space on your computer or smartphone.
- Tesseract is versatile and can be used for various tasks, from simple Optical Character Recognition (OCR) to more complex tasks such as Machine Learning (ML).
Cons of Tesseract
- Tesseract does not always produce perfect results, particularly with complex or handwritten text.
- Tesseract's image processing is rudimentary; therefore, you need to use a preprocessor or an image that has already been processed to obtain the best results [8].
ABBYY vs. Ephesoft

Ephesoft is another document recognition tool that uses optical character recognition (OCR) technology to convert images into text files. This software is designed specifically for businesses needing a solution for managing large volumes of paper documents such as invoices or receipts. Like ABBYY's products, Ephesoft can be used across multiple industries, including healthcare, government, finance, and manufacturing.
Both software suites offer a comprehensive range of features and benefits, but there are some critical differences between them. For example, ABBYY is generally considered more accurate than Ephesoft [6]t, especially when recognizing text in documents with complex layouts. However, Ephesoft is usually faster than ABBYY, making it a good choice for organizations that must process a large volume of documents daily. In terms of price, ABBYY is typically more expensive than Ephesoft, although both companies offer discounts for volume licensing. Ultimately, the best OCR software for your business will depend on your specific needs and budget.
Pros of Ephesoft
- The system has tracking functionality that helps track user document changes. This can be useful to prevent fraud and keep an eye on who made changes when multiple users work on a document.
- Ephesoft uses image quality enhancement techniques to extract data from images, such as OCR (Optical Character Recognition), barcode recognition, and character recognition. This increases data extraction accuracy significantly compared to manual methods, where the data may not be wholly accurate or complete due to poor image quality or other factors.
- Supports documents in multiple languages, such as English, Spanish, French, etc., making it suitable across industries with diverse customer bases that use different languages as their primary mode of communication/documentation.
Cons of Ephesoft
- It needs proper training before using it. If you don’t have prior experience working with this type of software, then you may find it difficult to use it effectively. However, once you get used to it, it will become very easy for you to use this product effectively in your business setting.
- Ephesoft software costs more than other similar products in the market. The initial investment required to purchase Ephesoft can be high, but the cost can be reduced by opting for a cloud version [7].
ABBYY vs. Hyperscience

Hyperscience’s proprietary machine learning models and powerful optical character recognition (OCR) technology bring unparalleled data extraction capability for handwritten forms, along with other structured and semi-structured documents. The platform boasts superior performance reporting, built-in quality assurance, and high-level extraction for accurate – and fast – document capture and analysis.
Both ABBYY and Hyperscience offer desktop and cloud-based OCR solutions. If you need to OCR a large volume of documents, ABBYY may be a better option, as you'll be able to process them in batches using the desktop application.
ABBYY's OCR engine is based on artificial intelligence (AI), while Hyperscience's OCR engine is based on machine learning (ML). This means that ABBYY can learn and improve over time, while Hyperscience will always produce results consistent with its training data. So if you need an OCR tool that can adapt to changing conditions (e.g., different fonts, poor quality images, etc.), ABBYY may be a better choice. However, if you need an OCR tool that will always produce the same high level of accuracy, regardless of the input document, Hyperscience may be a better option.
ABBYY vs. Readiris

Readiris is a powerful and accurate OCR engine that can be used to convert scanned documents and images into editable and searchable text. It offers a wide range of features and options, making it a versatile and powerful OCR solution for various needs.
Readiris is one of the popular alternatives to ABBYY FineReader. It is also an OCR program with a wide range of features and many users.
Pros of Readiris
- 20% faster document processing
- Edit texts embedded in your images with OCR
- Convert Microsoft Office documents to PDF
- Annotate and comment
- Protect and sign PDFs
- Integration with printers (Twain scanners) [3]
Cons of Readiris
- Pricing can be expensive when working with huge data.
- Accuracy can be low when working with unstructured data compared with other tools [4]
ABBYY vs. Google Cloud Vision

Google Cloud Vision OCR is a cloud-based text recognition and image analysis solution. The service uses deep learning algorithms to process images and videos, recognize objects, scenes, and faces, as well as detect text in more than 100 languages.
Pros of Google Cloud Vision
- The results are accurate and reliable—Google uses deep learning models for its OCR service, which means it learns more about how your specific document is formatted as time goes on, improving its accuracy over time.
- It's compatible with most file types—Google Cloud Vision OCR works with JPEG, PNG, BMP, TIFF, PDF files, and animated GIFs! You can even convert HTML pages into plain text using Google Cloud Vision OCR (although not all formatting will be preserved).
- It's easy to use—all you need to do is upload an image that contains the text you want to be converted and click "Create Text" in the Google Cloud Vision console. You don't need to install any software or download any software libraries.
- Provides API interface to integrate with custom software.
Cons of Google Cloud Vision
- It requires an internet connection (which means you cannot use it offline).
- It is slow to process large volumes of data. You can use it for small-to-medium amounts of text, but if you want to do large amounts of text processing in batch mode, this solution may not be fast enough for your needs.
- In some cases like table extraction, the accuracy of Google Cloud Vision OCR is not as high as other tools [5].
Want to automate data entry from documents? Nanonets' AI based OCR solution can help extract key information from structured/unstructured documents and put the process on auto-pilot!
ABBYY vs. Nanonets

Nanonets is an AI-based OCR software that automates data capture for intelligent document processing of invoices, receipts, ID cards, and more. Nanonets use advanced OCR, machine learning image processing, and Deep Learning to extract relevant information from unstructured data. It is fast, accurate, easy to use, allows users to build custom OCR models from scratch, and has some neat Zapier integrations. Digitize documents, extract data-fields, and integrate with your everyday apps via APIs in a simple, intuitive interface.
Pros of Nanonets
- Modern UI
- Handles large volumes of documents
- Reasonably priced
- Ease of use
- Cognitive capture of data - resulting in minimal intervention
- Requires no in-house team of developers
- Algorithm/models can be trained/retrained
- Great documentation & support
- Lots of customization options
- Wide choice of integration options
- Works with non-English or multiple languages
- Almost no post-processing required
- Seamless 2-way integration with multiple accounting software
- Great OCR API for developers
Cons of Nanonets
- Can’t handle very high volume spikes
- Table capture UI can be better.
Compare and Review ABBYY Pricing
Why choose Nanonets over ABBYY?
Nanonets is an OCR software that uses artificial intelligence to automate the extraction of tables from PDF documents, images, and scanned files. Unlike other solutions, it doesn’t require separate rules and templates for each new document type. Instead, it relies on cognitive intelligence to handle semi-structured and unseen documents while improving over time. You can also customize the output to only extract tables or data entries of your interest.
It is fast, accurate, easy to use, allows users to build custom OCR models from scratch, and has some neat Zapier integrations. Digitize documents, extract tables or data fields, and integrate with your everyday apps via APIs in a simple, intuitive interface.
Why is Nanonets the Best OCR?
- Nanonets can extract on-page data while command line PDF parsers only extract objects, headers & metadata such as (title, pages, encryption status, etc.)
- Nanonets PDF parsing technology isn't template-based. Apart from offering pre-trained models for popular use cases, Nanonets PDF parsing algorithm can also handle unseen document types!
- Apart from handling native PDF documents, Nanonet's in-built OCR capabilities allow it to handle scanned documents and images as well!
- Robust automation features with AI and ML capabilities.
- Nanonets handle unstructured data, common data constraints, multi-page PDF documents, tables, and multi-line items with ease.
- Nanonets is a no-code tool that can continuously learn and re-train itself on custom data to provide outputs requiring no post-processing.
Automated invoice parsing with Nanonets - creating completely touchless invoice processing workflows.
Integrate your existing tools with Nanonets and automate data collection, export storage, and bookkeeping.
Nanonets can also help in automating invoice parsing workflows by:
- Importing and consolidating invoice data from multiple sources - email, scanned documents, digital files/images, cloud storage, ERP, API, etc.
- Capturing and extracting invoice data intelligently from invoices, receipts, bills, and other financial documents.
- Categorizing and coding transactions based on business rules.
- Setting up automated approval workflows to get internal approvals and manage exceptions.
- Reconciling all transactions.
- Integrating seamlessly with ERPs or accounting software such as Quickbooks, Sage, Xero, Netsuite, and more.
References
[1] Can I recognize handwritten text in ABBYY FineReader? – Help Center
[2] ABBYY FineReader VS Amazon Textract - compare differences & reviews?
[3] 7 Best OCR Software of 2022 (Free and PAID)
[4] Top 10 OCR software in 2022 | Best OCR solutions
[6] Ephesoft vs. FineReader PDF for Windows and Mac 2022 | G2



